
Scaling Law Is Not Done Yet
Many in the AI community have argued that the Scaling Law is showing diminishing returns, questioning the rationale of training ever-larger models. Recent observations, however, paint a different picture: even minimal improvements in single-step accuracy can compound to enable exponential task-length growth, which may carry more real-world value than raw benchmark scores suggest.

While the marginal gains from increasing compute scale are decreasing, is it still reasonable for companies to invest heavily in larger models? This debate has intensified in the AI field over the past year.
Long-Horizon Task Performance Outweighs Short-Step Gains
A recent paper titled “The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs” offers a fresh perspective:
- Paper link: arXiv:2509.09677
- Code: GitHub
- Dataset: Hugging Face
The research emphasizes that long-horizon task completion has historically been a weak spot for deep learning. Stunning demos in autonomous driving and image generation exist, but achieving long-term, coherent execution (like a multi-step project or a long video) remains a challenge. Companies increasingly demand AI to handle entire workflows, not just isolated questions. This raises a fundamental question: how do we measure the number of steps an LLM can reliably execute?
Execution vs. Planning
Failures in long tasks are often interpreted as reasoning limitations. While LLMs have made significant progress on complex reasoning benchmarks, some studies (e.g., The Illusion of Thought, arXiv:2506.06941) suggest models merely give the illusion of reasoning, ultimately failing as task length grows.
The new research argues for decoupling planning from execution:
- Planning decides what information or tools to use and in what order.
- Execution turns the plan into reality.
Even when planning is perfect, execution errors accumulate with longer tasks. Execution, not planning, is the critical bottleneck for long-horizon LLM performance. As LLMs are increasingly deployed in extended reasoning or agent-based tasks, this distinction grows in importance.

Key Findings
1. Scaling Still Matters
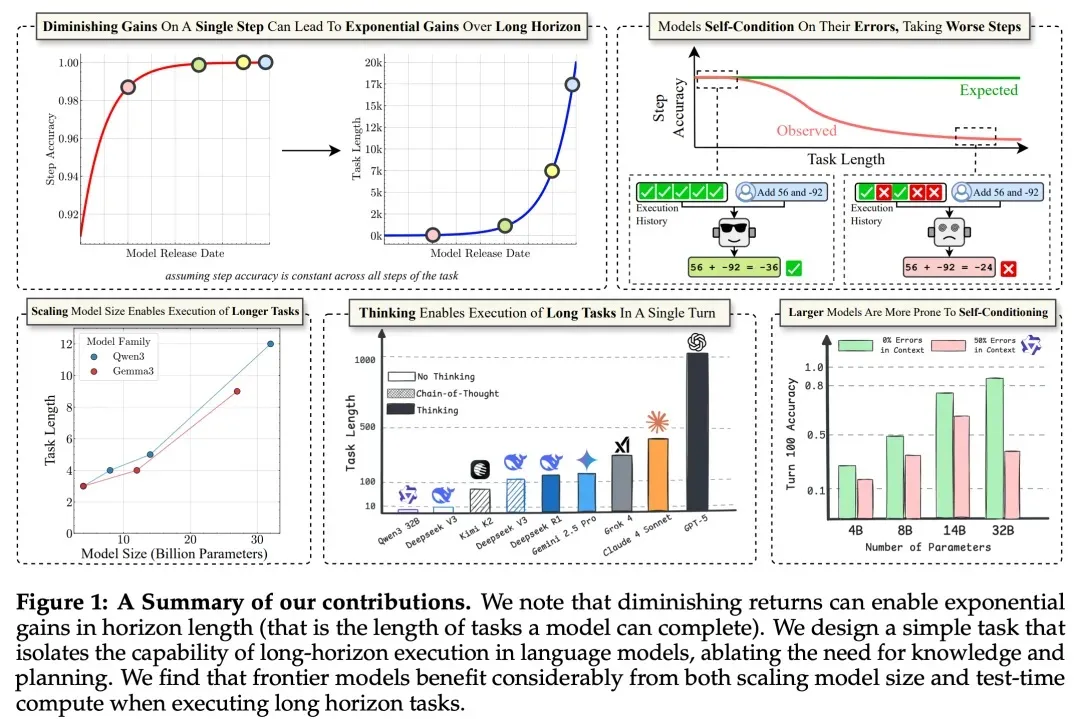
Although single-step accuracy improvements diminish, tiny gains compound, enabling exponential growth in task length. Larger models succeed in more rounds even when provided explicit knowledge and planning, showing that scaling benefits go beyond memory or search abilities.
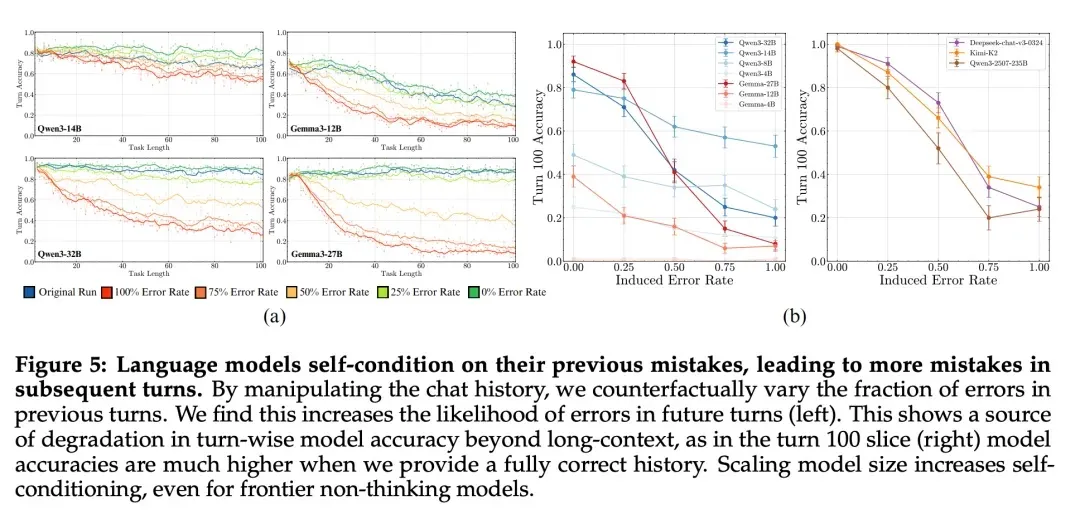
2. Self-Conditioning Effect
Long-task failures aren’t only due to steady per-step errors. LLMs tend to increase their error rate over steps: if previous outputs contain mistakes, the likelihood of future mistakes rises. This contrasts with humans, who usually improve with practice. Self-conditioning is exacerbated by next-token prediction training, and scaling alone cannot resolve it.
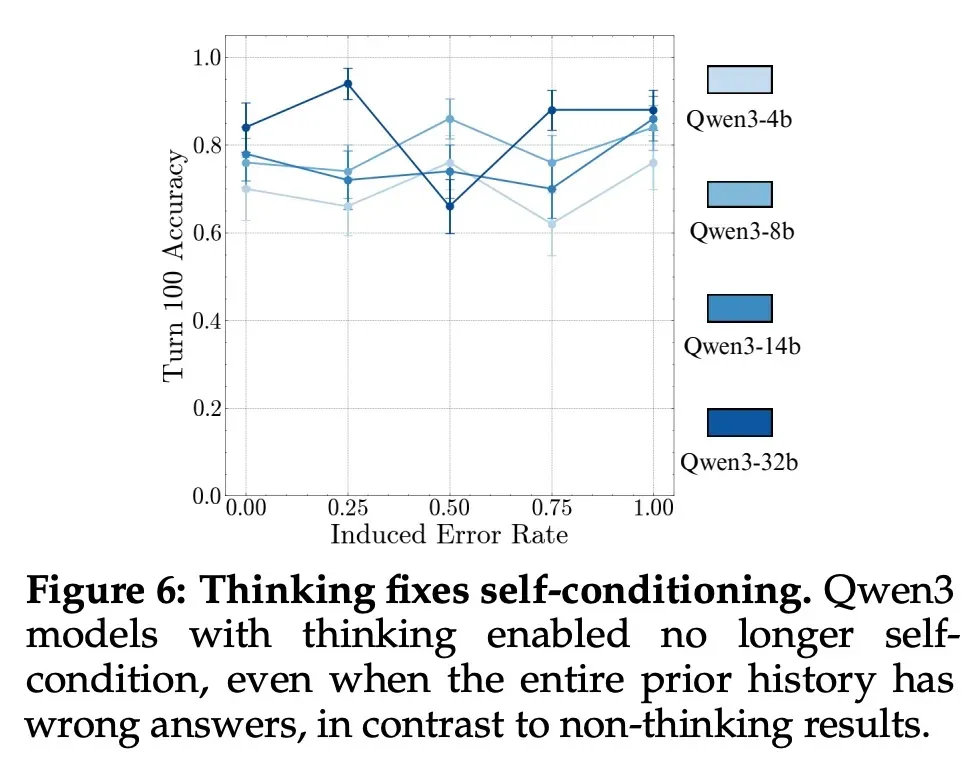
3. Chain-of-Thought (CoT) Matters
Recent thinking models can correct self-conditioning. Sequential test-time compute boosts the task length achievable in a single round. For instance:
- Non-thinking models like DeepSeek V3 fail after 2 steps.
- Thinking variants like R1 succeed for 200 steps.
GPT-5’s thinking variant (Horizon) executes over 1,000 steps, far surpassing competitors like Claude-4-Sonnet at 432 steps.
Long-task execution failures should not be mistaken for reasoning deficiencies. Increased model scale and sequential compute allocation significantly improve long-horizon performance. Economic value often correlates with total task length rather than short benchmarks.

Detailed Methodology
Step Accuracy vs. Task Length
The authors analyze the relationship between single-step accuracy and task success, assuming:
- Step accuracy (p) is constant.
- No self-correction occurs.
Under these assumptions, the expected task length (H) at success probability (s) is derived as:
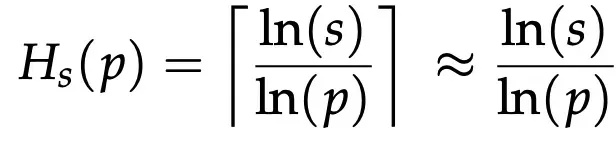
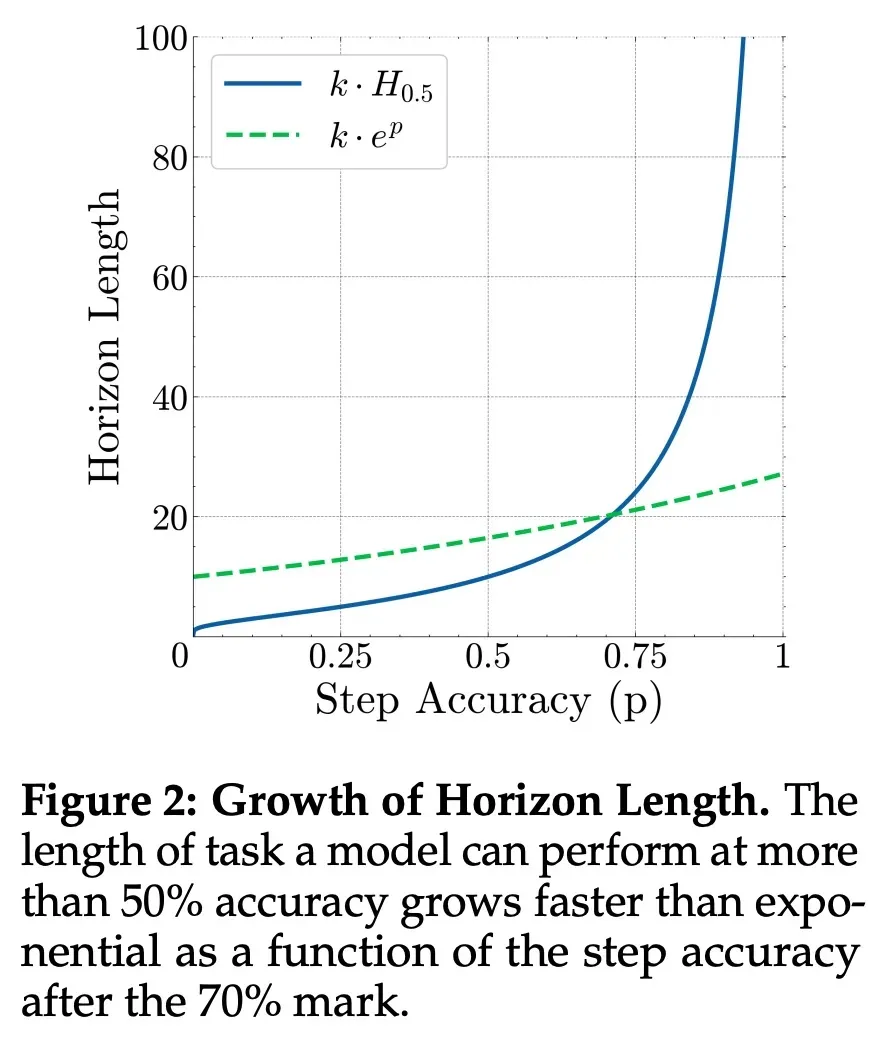
For step accuracy above 70%, small gains lead to super-exponential task-length improvements, confirming that diminishing returns on short benchmarks do not imply stagnation in long-horizon tasks.
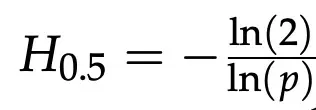
Isolating Execution by Decoupling Planning
Using a flight-booking agent example:
- Planning: decides which flights to evaluate and in what order.
- Execution: retrieves information, combines it, and updates state.
By providing all planning keys and associated knowledge, the study isolates execution as the variable, focusing on task length determined by rounds × steps per round (K).
Experimental Insights
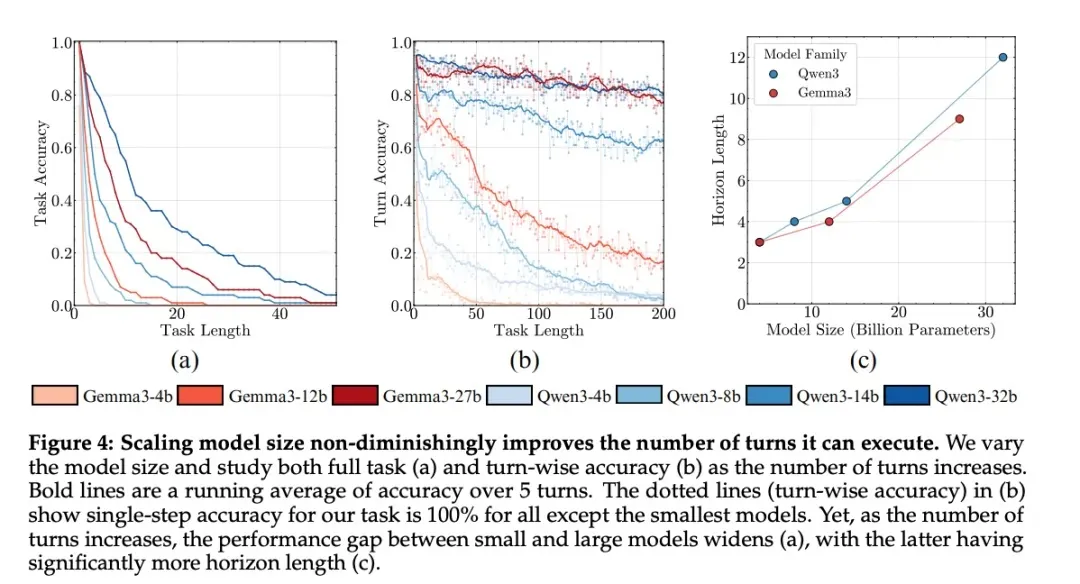
Scaling Boosts Long-Horizon Execution
Even when world knowledge and planning are controlled:
- Larger models maintain higher accuracy across more rounds.
- Accuracy per round still declines due to self-conditioning.
- Thinking models overcome self-conditioning and execute longer tasks per round.
Self-Conditioning Explained
- Accuracy declines with rounds because models “condition” on their previous errors.
- Self-conditioning, unlike long-context degradation, is not mitigated by model scaling.
- Thinking models (e.g., Qwen3 CoT) avoid self-conditioning, maintaining stable accuracy regardless of previous errors.
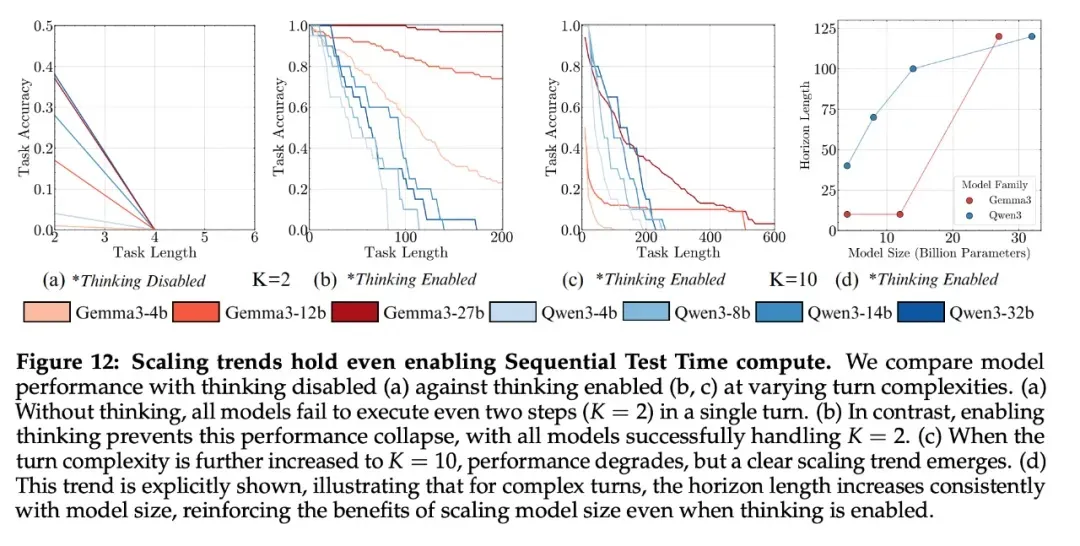
Task Length per Round
- Non-thinking models struggle with even 2-step tasks per round.
- With CoT reasoning, models perform significantly longer single-round tasks.
- Sequential compute is more effective than parallel testing for long-horizon tasks.
GPT-5 Horizon demonstrates a massive lead over other models in single-round task length, and RL-trained thinking models outperform instruction-tuned counterparts.

Conclusion
Long-horizon execution remains a major challenge, especially for open-source weights compared to API-only models. Scaling model size and enabling reasoning mechanisms (CoT, sequential compute) significantly increase the practical task length, overturning assumptions of diminishing returns. This study encourages developing benchmarks focused on execution depth to accurately measure LLM scaling benefits.