
Since its introduction in 2014, Adam and its improved variant AdamW have dominated the pretraining of open-weight language models. Their ability to maintain stability and achieve fast convergence on massive datasets has made them the go-to choice in large-scale model training.
Why Optimizers Matter in Pretraining
As model sizes grow exponentially, pretraining has become one of the most compute-intensive bottlenecks in AI research, often representing the bulk of development cost. In this setting, the choice of optimizer directly determines convergence speed and training efficiency.
Researchers have proposed multiple directions of improvement. Some of the fastest alternatives adopt matrix-based preconditioners (e.g., Muon, Soap, Kron), offering 30–40% per-iteration speedups compared with a carefully tuned AdamW.
But the latest study from Stanford University’s Percy Liang group reveals a more nuanced picture:
while many optimizers claim 1.4–2× training speedups, AdamW remains the most robust and reliable choice for pretraining. Matrix-based optimizers do show clear advantages — but only under specific data-to-model scaling regimes.

- Paper: Fantastic Pretraining Optimizers and Where to Find Them
arXiv (PDF) - GitHub Discussion: marin-community/marin#1290
- Project Blog: wandb.ai report
Why Previous Comparisons May Be Misleading
The Stanford team highlights two methodological flaws in prior claims of breakthrough performance:
1. Unfair Hyperparameter Tuning
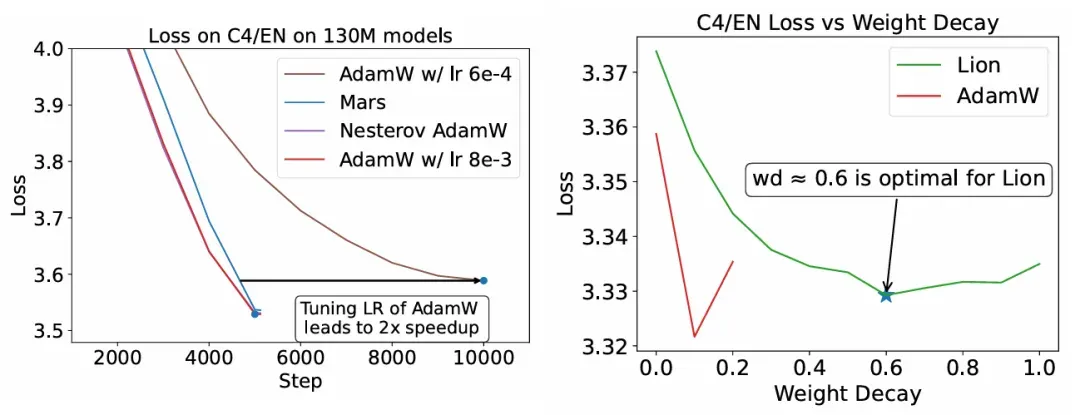
- Baseline models were often under-tuned. For example, simply tuning the learning rate in AdamW can double training speed for a 130M-parameter model.
- Shared fixed hyperparameters across optimizers are not fair. Optimizers like Lion prefer higher weight decay (≈0.6) than the standard 0.1 used in AdamW, which skews comparisons.
2. Insufficient Scale Testing
- Many benchmarks only use small models (<1B parameters) or 1× Chinchilla compute scaling, which may not generalize.
- Early checkpoint results can be misleading — loss curves often cross during learning rate decay, flipping rankings. Proper evaluations must rely on end-of-training performance across multiple scales.
The Study: A Systematic Benchmark
The researchers conducted a large-scale evaluation of 11 different optimizers, across model sizes from 130M to 1.2B parameters and data-to-model ratios ranging from 1× to 8× Chinchilla-optimal.
Key Findings
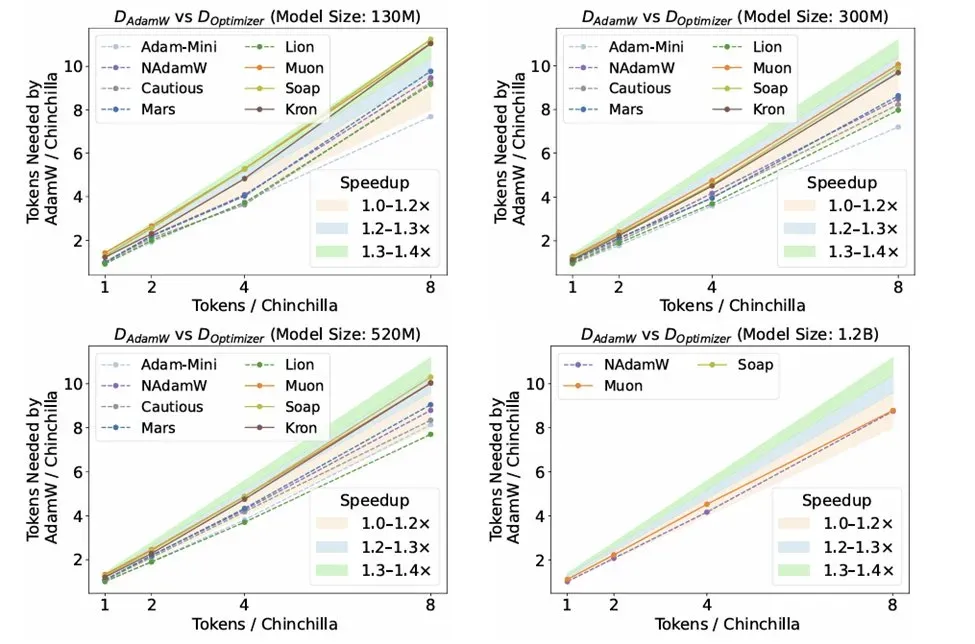
- Independent tuning is critical. Optimal hyperparameters differ significantly across optimizers. Without separate tuning, claims of speedup collapse against a well-tuned AdamW.
- Short-term metrics are unreliable. Rankings can reverse as training progresses.
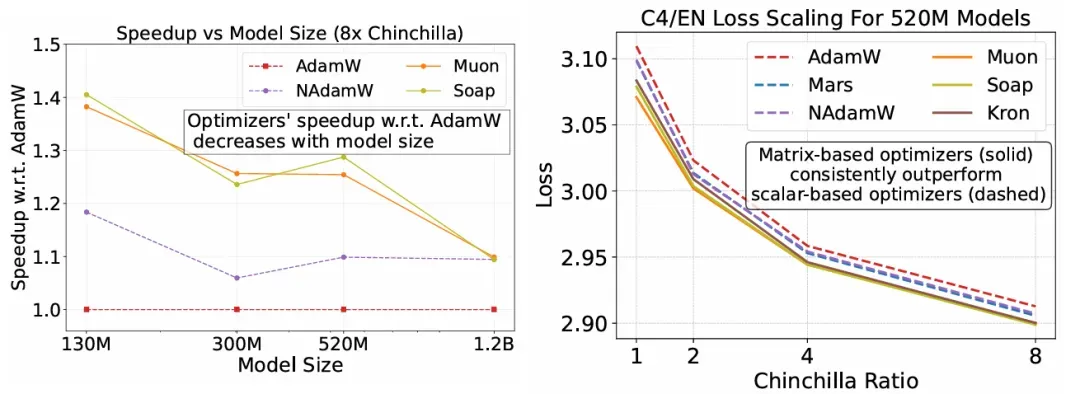
- Matrix-based optimizers consistently lead. Muon, Soap, and Kron outperform scalar-based methods, achieving 30–40% per-step speedups over tuned AdamW.
- Best optimizer depends on data regime. Muon dominates at standard ratios, but Soap becomes superior at ≥8× Chinchilla scaling.
Methodology in Detail
The evaluation followed a three-phase methodology:
Phase I: Exhaustive Parameter Scans
- Conducted grid searches on hyperparameters (LR, weight decay, warmup steps, β₁, β₂, ε, grad clipping, batch size).
- Benchmarked across 130M–500M models at 1× Chinchilla, and 130M models at 2×–8× ratios.
- Found that many reported gains vanish when AdamW is fairly tuned.
Phase II: Identifying Sensitive Parameters
- Identified sensitive hyperparameters (e.g., LR, warmup length) that shift with model scale.
- Performed deeper tuning across larger models and higher data regimes.
- Used fitted scaling laws to quantify relative speedups vs. AdamW.
- Result: Matrix optimizers rarely exceeded 1.4× real-world speedup.
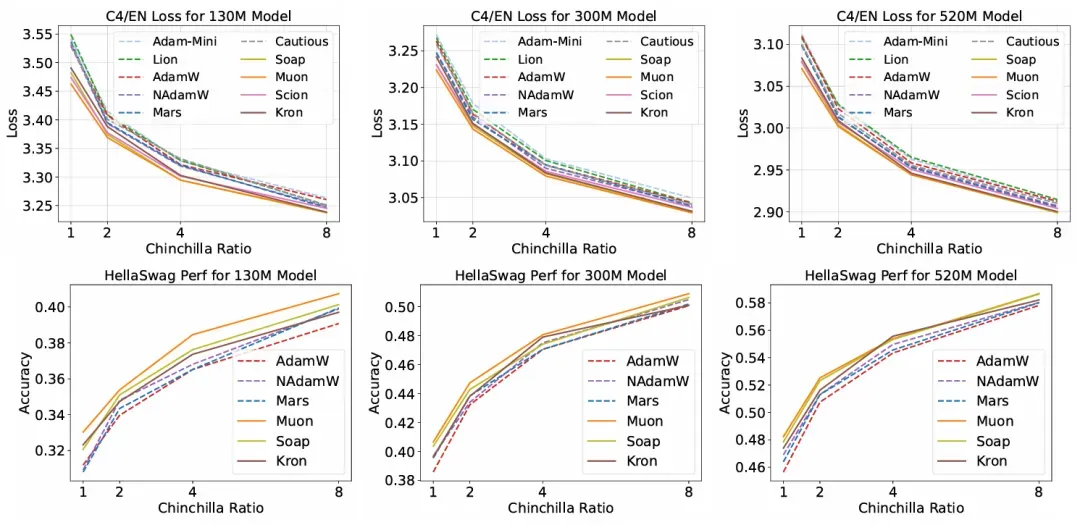
Phase III: Case Studies at Scale
- Tested on 1.2B models and extreme data ratios (up to 16× Chinchilla).
- Muon remained faster than AdamW, but speedups shrank to ≤1.2×.
- At extreme ratios, Soap and NAdamW overtook Muon, showing better stability in high-data regimes.
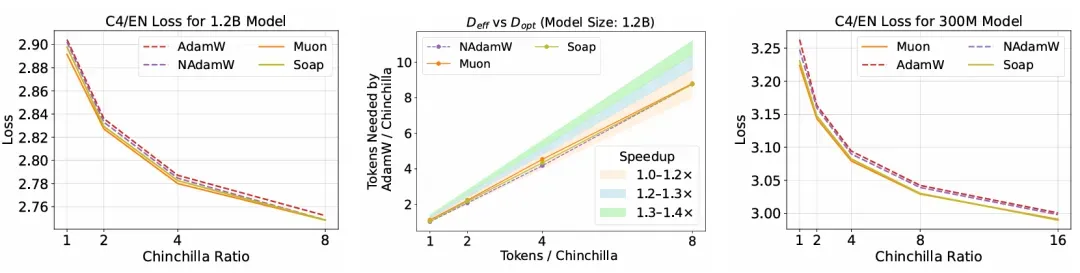
Conclusion: Stability Wins
The Stanford study offers a sobering takeaway:
- AdamW remains the most stable and trustworthy choice for pretraining, despite flashy claims of alternatives.
- Matrix-based optimizers do provide consistent gains, but these gains shrink at scale, rarely exceeding ~1.4× acceleration in practice.
- The “best” optimizer is context-dependent — Muon leads in standard setups, but Soap shines in extreme data-to-model ratios.
For practitioners, the message is clear: fair hyperparameter tuning and large-scale testing matter far more than chasing the latest optimizer hype.