
AI’s most notorious bug is not a system crash—but hallucinations: when a model confidently fabricates information, blurring the line between fact and fiction. This persistent challenge has long been the barrier to fully trusting AI systems.
OpenAI has now released a rare research paper that takes a systematic look at the root causes of hallucinations in large language models (LLMs). The paper is titled “Why Language Models Hallucinate” and can be accessed here:
👉 Why Language Models Hallucinate (PDF)

What Are Hallucinations?
OpenAI defines hallucinations simply as:
“When a model confidently generates an untrue answer.”
Hallucinations are not limited to complex problems. Even seemingly simple queries can trigger them. For example, when asked about the PhD thesis title of Adam Tauman Kalai (the paper’s first author), several widely used chatbots confidently gave three different answers—none of which were correct.

Similarly, when asked about his birthday, the models provided three different—but all wrong—dates.

Why Do They Happen?
The paper argues that hallucinations persist largely because current training and evaluation methods create the wrong incentives.
- Models are typically rewarded for guessing rather than for acknowledging uncertainty.
- Accuracy-driven metrics (i.e., how often answers are “right”) unintentionally encourage speculation.
Consider a multiple-choice exam:
- If you guess, you might get lucky.
- If you leave it blank, you get zero.
Under accuracy-only scoring, guessing always looks better than admitting “I don’t know.”
This is why models often opt for confident but wrong answers rather than safe disclaimers.
The Evaluation Trap
OpenAI emphasizes that evaluation metrics are a key driver of hallucinations.
- Accuracy rewards guesses.
- Errors (hallucinations) are penalized less than leaving a question unanswered.
- This creates a “leaderboard culture” where systems optimized for accuracy appear stronger, even if they hallucinate more often.

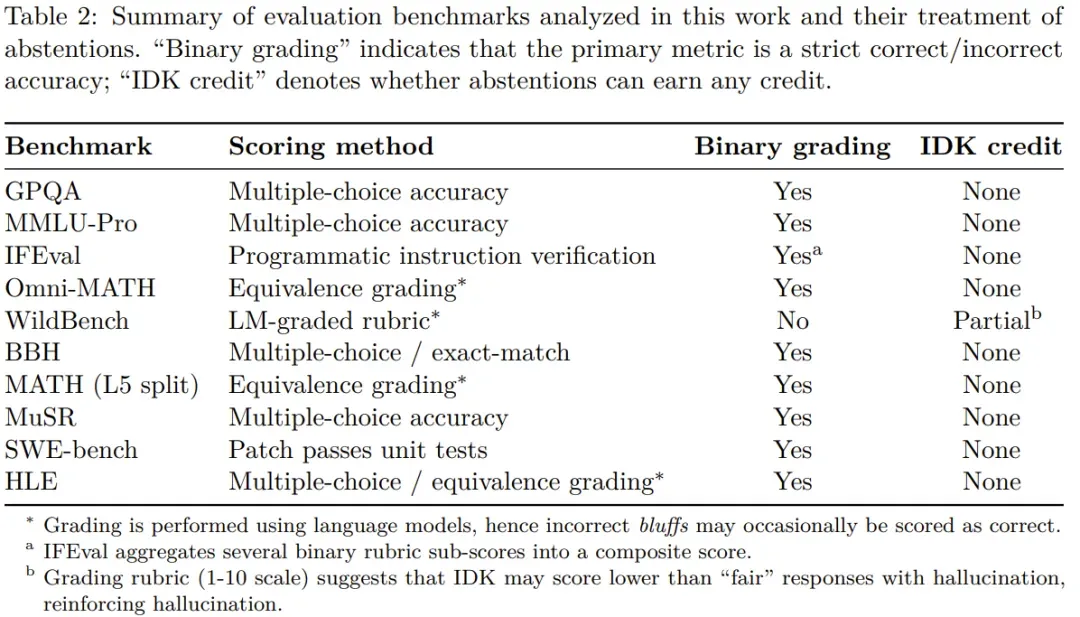
OpenAI argues that instead of rewarding only accuracy, evaluations should penalize confident errors more heavily and grant partial credit for admitting uncertainty. This aligns with OpenAI’s value of humility.
How Hallucinations Arise from Next-Word Prediction
Language models learn via pretraining on vast amounts of text by predicting the next word. Unlike typical supervised learning, there are no explicit “true/false” labels.
- Patterns like spelling or grammar are consistent and predictable, so errors vanish as models scale.
- But rare factual details—like a person’s birthday—are essentially random and cannot be reliably inferred from patterns.
This statistical mismatch explains why hallucinations emerge: LLMs excel at fluency but stumble on low-frequency factual knowledge.
Key Misconceptions, Debunked
OpenAI’s analysis challenges several common beliefs:
-
Claim: Hallucinations disappear if accuracy reaches 100%.
- Finding: Accuracy will never be 100%, as some real-world questions are unanswerable.
-
Claim: Hallucinations are inevitable.
- Finding: Models can avoid hallucinations by declining to answer when uncertain.
-
Claim: Only larger models can avoid hallucinations.
- Finding: Smaller models sometimes handle uncertainty better by openly admitting “I don’t know.”
-
Claim: Hallucinations are a mysterious flaw of modern AI.
- Finding: Their origins can be understood statistically—hallucinations are rewarded by evaluation practices.
-
Claim: All we need is a better hallucination benchmark.
- Finding: Single benchmarks don’t solve the issue; the entire evaluation ecosystem must be redesigned.
Toward Better Evaluation
OpenAI suggests a straightforward fix:
- Punish confident errors more than uncertainty.
- Reward clear expressions of uncertainty.
This approach echoes standardized tests that use negative marking for wrong answers or partial credit for blanks, discouraging blind guessing.
Adopting such metrics at scale could drive the adoption of techniques that reduce hallucinations—not just in OpenAI models, but across the entire field.
Broader Context: Organizational Shifts at OpenAI
Alongside the paper, TechCrunch reports that OpenAI is reorganizing its Model Behavior team—the group responsible for shaping how AI systems interact with people. The team will now report to Max Schwarzer, OpenAI’s post-training lead.
Meanwhile, founding head Joanne Jang announced a new initiative: oai Labs, a research-focused group dedicated to inventing and prototyping new ways for humans and AI to collaborate.
