
The second Artificial Intelligence Mathematical Olympiad (AIMO2) has delivered groundbreaking results. While NVIDIA’s NemoSkills topped the leaderboard in the previous edition, this year, OpenAI’s o3 model entered the competition for the first time—and swept the stage with near-perfect scores.
Even the legendary mathematician Terence Tao expressed excitement, noting that the competition had previously been limited to open-source participants with constrained compute budgets. With o3’s entry, the gap between commercial and open-source AI reasoning systems has become clearer than ever.
Key Highlights of AIMO2
- Participants: NemoSkills (NVIDIA), Imagination Research (Tsinghua + Microsoft), and OpenAI o3
- Evaluation Modes:
- Compute-matched: roughly equal resources for all teams
- Compute-unbounded: models free to run at higher capacity
- Findings: More compute directly correlates with better performance.
With compute fully unleashed, OpenAI’s o3 achieved 47/50 (near full marks). In fact, given two attempts per problem, the model could plausibly score a perfect 50/50.
Interestingly, under compute-matched conditions, open-source and closed-source models showed only marginal differences, underscoring how much scaling impacts performance.

📄 Full report: The Gap Is Shrinking
Olympiad-Level Math, AI-Style
The AIMO benchmark targets Olympiad-grade mathematical reasoning—a notoriously difficult domain for machines.
- The performance gap between open-source and commercial AI is shrinking.
- Open models are approaching parity with closed models in high-level reasoning.
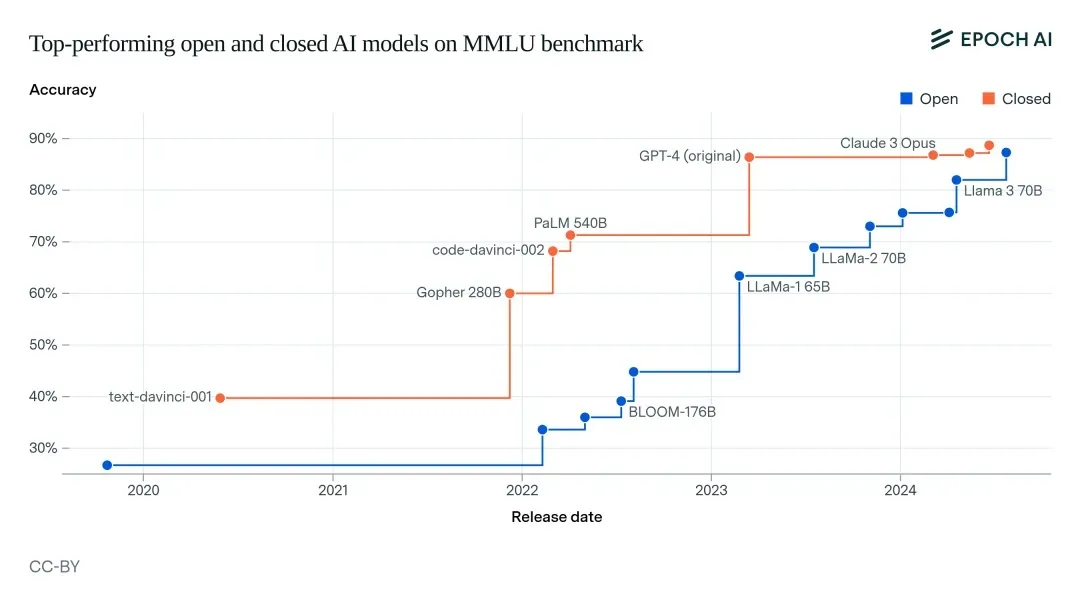
This aligns with Epoch AI’s 2024 forecast, which estimated open-source AI would lag closed systems by about one year in reasoning capabilities.
Launched in 2023, the Artificial Intelligence Mathematical Olympiad was designed to accelerate progress in open, reproducible, high-level mathematical reasoning.

🔗 Competition Portal: Kaggle AIMO2
AIMO2: Raising the Difficulty
The second edition, completed in April 2025, increased problem difficulty to match national Olympiads like the UK’s BMO and the US USAMO.
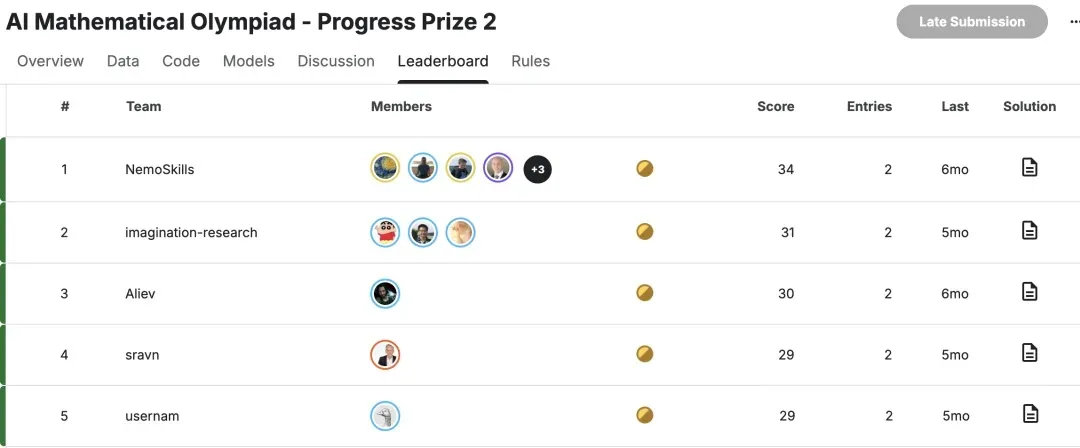
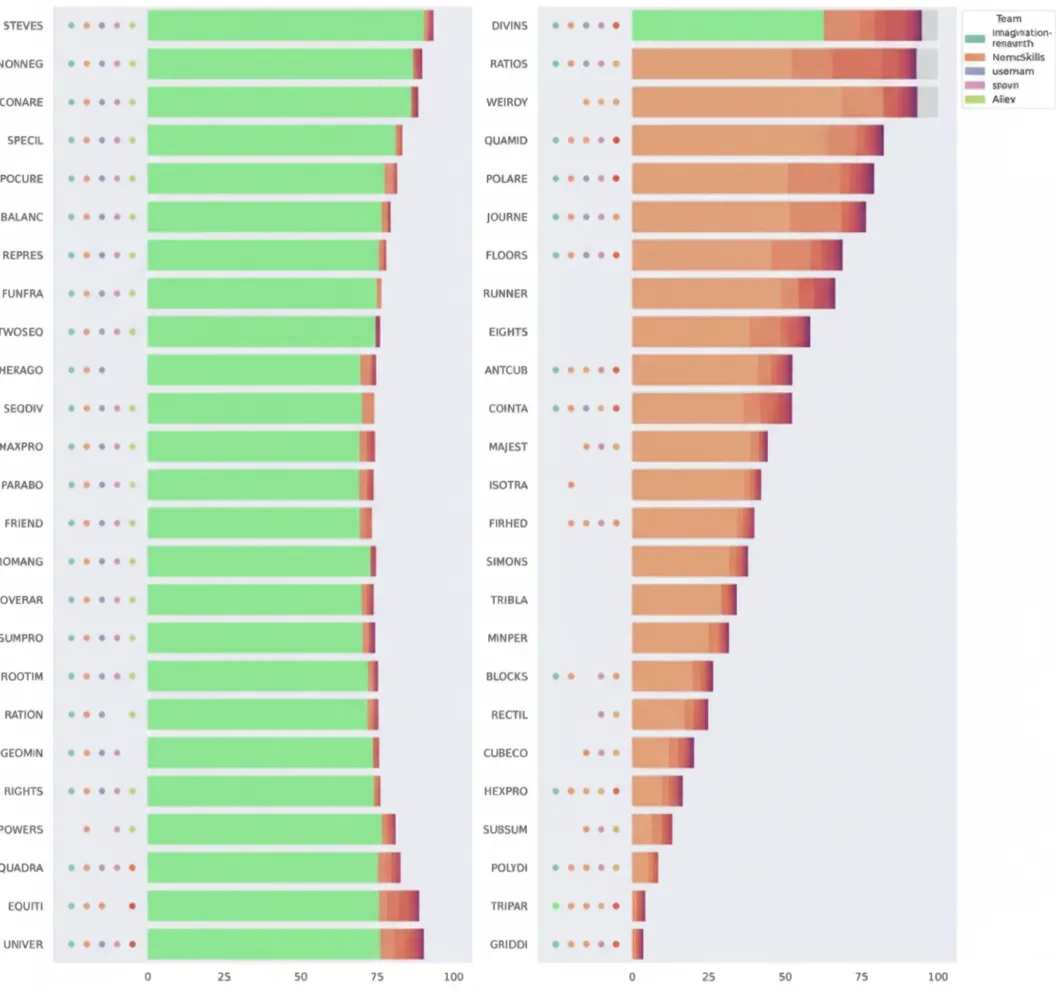
AIMO2 Leaderboard (Private Scores)
- NemoSkills: 34/50 (public: 33/50)
- Imagination Research: 31/50 (public: 34/50)
- Aliev: 30/50 (public: 28/50)
- sravn: 29/50 (public: 25/50)
- usernam: 29/50 (public: 25/50)
Kaggle uses two leaderboards:
- Public leaderboard: live feedback during the contest
- Private leaderboard: final evaluation on a hidden test set to avoid overfitting or leakage
Despite harder problems than AIMO1, the results were remarkably strong.
But a bigger question loomed: What happens when closed-source AI like OpenAI’s o3 is tested head-to-head?
OpenAI o3 vs. AIMO2 Champions
OpenAI partnered with AIMO organizers to evaluate o3-preview (a pre-release version) against Olympiad math benchmarks.
Comparison included:
- o3-preview (general-purpose model, not math-specialized)
- Top 2 AIMO2 open-source models
- AIMO2-combined: results merged across all 2000+ Kaggle teams (a “best of all worlds” scenario)
Results:
- o3-preview (high compute): ~47–50/50
- AIMO2-combined: 38/50
- Gap: roughly 5 points, showing open-source is closing in
Crucially, when compute cost is factored in, open-source models appear far more competitive.
o3 Performance Across Compute Levels
Three configurations were tested:
- Low compute
- Medium compute
- High compute (with sample-and-rank scoring)
Scores:
- o3-preview high compute (top-2 answers): 50/50
- o3-preview high compute (top-1 answers only): 47/50
- o3-preview medium compute: 46/50
- o3-preview low compute: 43/50

Even at low compute, o3 solved 7 more problems than NemoSkills’ champion model, despite NemoSkills being run on stronger hardware.
NVIDIA and Tsinghua Reruns on H100
To test full potential, top open-source teams reran their models on 8×H100 GPUs (640GB VRAM), compared to the original Kaggle cap of 4×L4 GPUs (96GB VRAM).
Results:
- NemoSkills: 35/50 (up from 33/50)
- Imagination Research: 35/50 (up from 34/50)
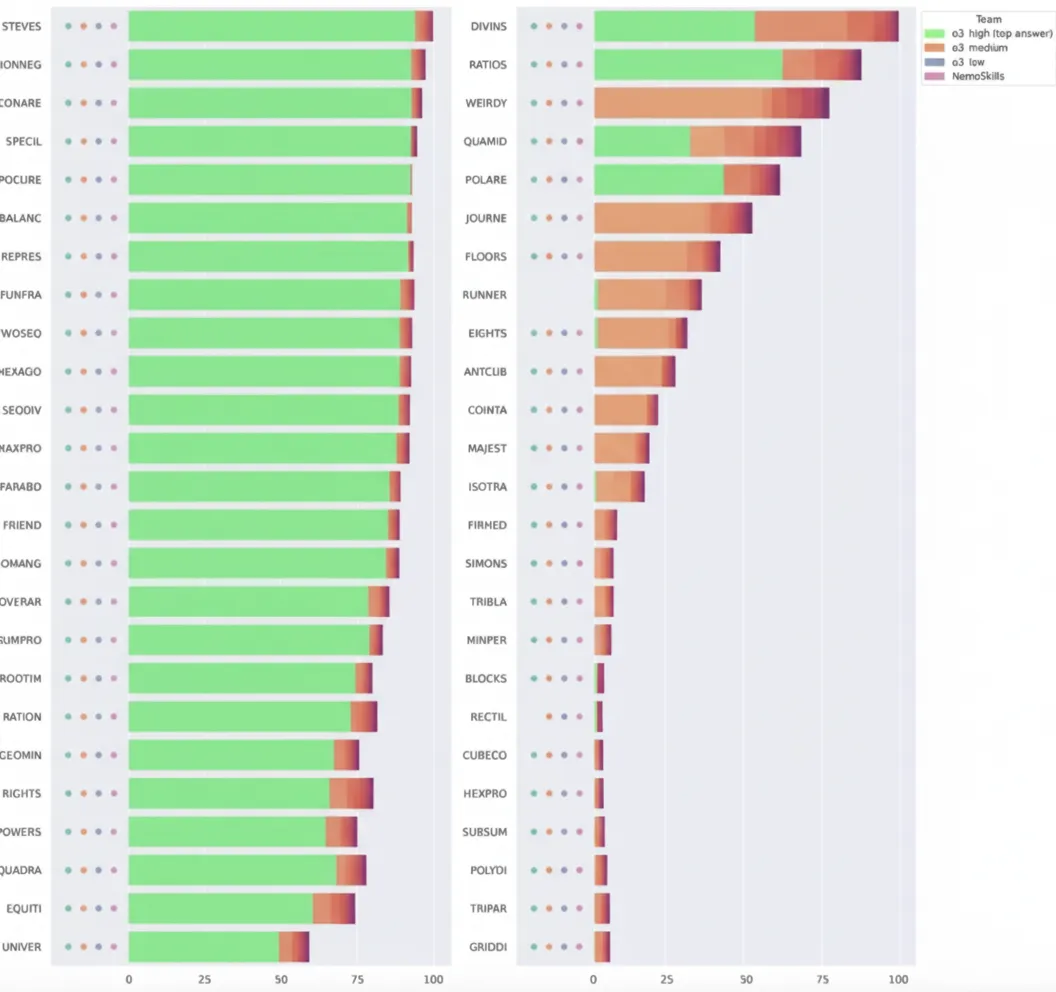
Even with vastly more compute, their gains were modest—just 1–2 points—highlighting the scaling edge of o3.
Open vs. Closed: The Shrinking Gap
AIMO organizers caution that score types differ:
- AIMO2-combined (47/50) resembles pass@2k+, where at least one of thousands of attempts is correct.
- o3 scores (43–50/50) are pass@1 style—stricter single-attempt evaluations.
Nonetheless, the conclusion is clear: closed-source AI still leads, but open-source AI is catching up faster than expected.
Looking Ahead: AIMO3
The competition’s next edition, AIMO3, launches in Fall 2025, with IMO-level difficulty at the core. Details on schedule, prize pool, and new competition rules will be released soon.
This year’s results already mark a milestone in AI reasoning performance—suggesting that solving Olympiad-level mathematics may soon be within reach of open-source AI systems.
📚 References: