
At Tuesday’s AI Infrastructure Summit, NVIDIA introduced the Rubin CPX (Rubin Context GPUs), a new GPU purpose-built for long-context inference workloads that exceed 1 million tokens.
For developers and creators, this breakthrough means more powerful performance across demanding tasks such as software development, long-form video generation, and research applications.
In software engineering, for example, AI systems need to reason across entire repositories—understanding project-level structures to provide meaningful assistance. Similarly, in long video generation or scientific research, models must sustain coherence and memory across millions of tokens. With the release of Rubin CPX, these bottlenecks are finally being addressed.

A New Era of AI Infrastructure: Vera Rubin NVL144 CPX Platform
The Rubin CPX GPU will integrate seamlessly with NVIDIA Vera CPUs and Rubin GPUs, powering the new NVIDIA Vera Rubin NVL144 CPX platform. This MGX-based system delivers:
- 8 exaflops of AI compute within a single rack
- 7.5× the AI performance of NVIDIA’s GB300 NVL72 system
- 100TB of high-speed memory
- 1.7 PB/s of memory bandwidth
To support existing customers, NVIDIA will also offer Rubin CPX compute trays for upgrading current Vera Rubin NVL144 systems.


NVIDIA Vera Rubin NVL144 CPX rack and compute trays with Rubin CPX, Rubin GPUs, and Vera CPUs.
Jensen Huang: “A Leap Forward for AI Computing”
NVIDIA founder and CEO Jensen Huang described the launch as a defining moment:
“The Vera Rubin platform marks another leap forward at the frontier of AI computing. Not only does it introduce the next-generation Rubin GPUs, but also a new class of processors: CPX. Just as RTX transformed graphics and physical AI, Rubin CPX is the first CUDA GPU designed for large-scale context, enabling inference across millions of tokens in one pass.”
The industry response has been immediate: a game-changer for creators, developers, and researchers alike.
Rubin CPX: Breaking Through the Context Barrier
Large language models are evolving into intelligent agents capable of multi-step reasoning, persistent memory, and long-context comprehension. But these advances push infrastructure to its limits across compute, storage, and networking—demanding a fundamental rethinking of inference scaling.
Decoupled Inference Architecture
NVIDIA’s SMART framework provides the blueprint:
- A full-stack, decoupled architecture for efficient compute and memory orchestration
- Leveraging GB200 NVL72 (Blackwell architecture), NVFP4 low-precision inference, and software like TensorRT-LLM and Dynamo
- Delivering record-breaking throughput and efficiency
Inference workloads split into two distinct phases:
- Context processing — compute-intensive, requiring massive throughput to ingest and analyze data for the first token.
- Content generation — memory bandwidth-bound, dependent on NVLink interconnects for sustained per-token performance.
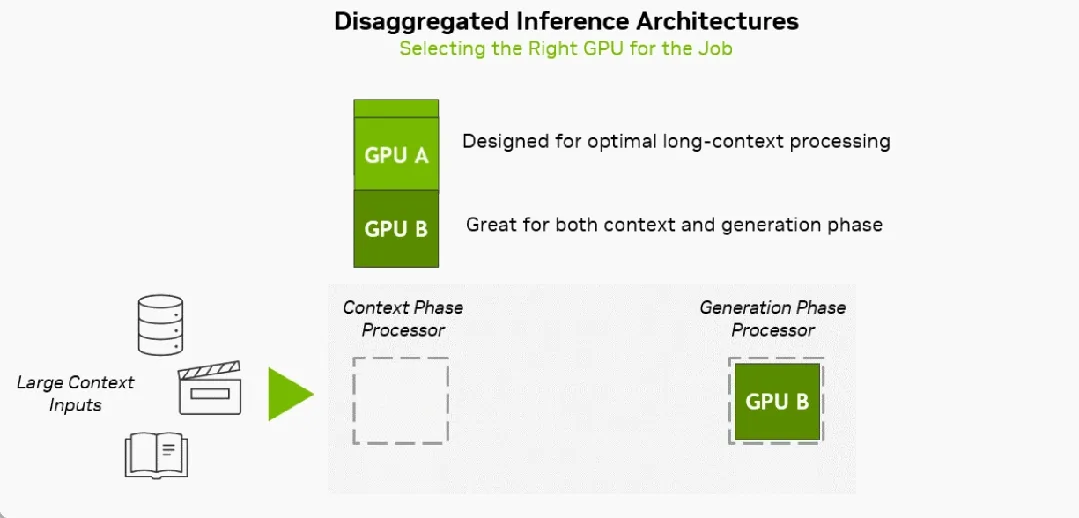
By decoupling these phases, NVIDIA enables precise optimization of compute vs. memory resources—boosting throughput, cutting latency, and maximizing utilization.
The orchestration layer is NVIDIA Dynamo, a modular, open-source inference framework that already set new records in MLPerf benchmarks through decoupled inference on the GB200 NVL72.
Rubin CPX: Purpose-Built for Long-Context Inference
Against this backdrop, Rubin CPX GPU arrives as a specialized solution for long-context workloads:
- NVFP4 precision compute with up to 30 petaflops performance
- 128GB of cost-efficient GDDR7 memory
- 3× improvement in attention processing compared to GB300 NVL72 systems
- Single-die architecture optimized for performance and energy efficiency
These enhancements ensure faster, more stable performance when handling multi-million-token sequences.

Industry Applause: From Code to Creativity
-
Michael Truell, CEO of Cursor:
“With NVIDIA Rubin CPX, Cursor can deliver lightning-fast code generation and deep developer insights—redefining how software is created and unlocking unprecedented productivity.”
-
Cristóbal Valenzuela, CEO of Runway:
“Video generation is moving toward longer contexts and agent-driven workflows. Rubin CPX’s performance leap empowers creators with speed, realism, and control—from indie artists to large studios.”
Availability
The NVIDIA Rubin CPX GPU is expected to launch in late 2026.
Until then, the industry eagerly awaits what is being hailed as the “beast” of context inference computing.