
Meta’s Superintelligence Lab has officially entered the research stage — and it’s not pulling any punches.
Its very first paper introduces REFRAG, a selective decoding framework that could reshape Retrieval-Augmented Generation (RAG) as we know it.
The claim: up to 30× faster Time-to-First-Token (TTFT) while preserving accuracy.

📄 Paper: https://arxiv.org/abs/2509.01092
Why RAG Needed Fixing
RAG has been the go-to solution for extending Large Language Models (LLMs) beyond their frozen, parameterized knowledge. By retrieving relevant documents from external sources and feeding them into the model, RAG delivers more accurate, up-to-date answers.
But this comes at a steep cost:
- Longer contexts slow everything down
- Compute scales quadratically with input size
- Time-to-First-Token (TTFT) balloons — a dealbreaker for real-time apps

In short, RAG’s promise of accuracy often collides with the harsh reality of efficiency.
Meta’s Breakthrough: Cut the Redundancy
Meta’s researchers found that LLMs don’t treat all retrieved documents equally.
Attention maps showed a block-diagonal pattern:
- Strong within a single document
- Strong between query and relevant passages
- Weak across unrelated docs
Yet Transformers still perform full global attention, wasting compute on low-value interactions.
The fix? Skip the waste.
Enter REFRAG.
Inside REFRAG: Compress, Sense, Expand
REFRAG optimizes context processing with a three-step pipeline:
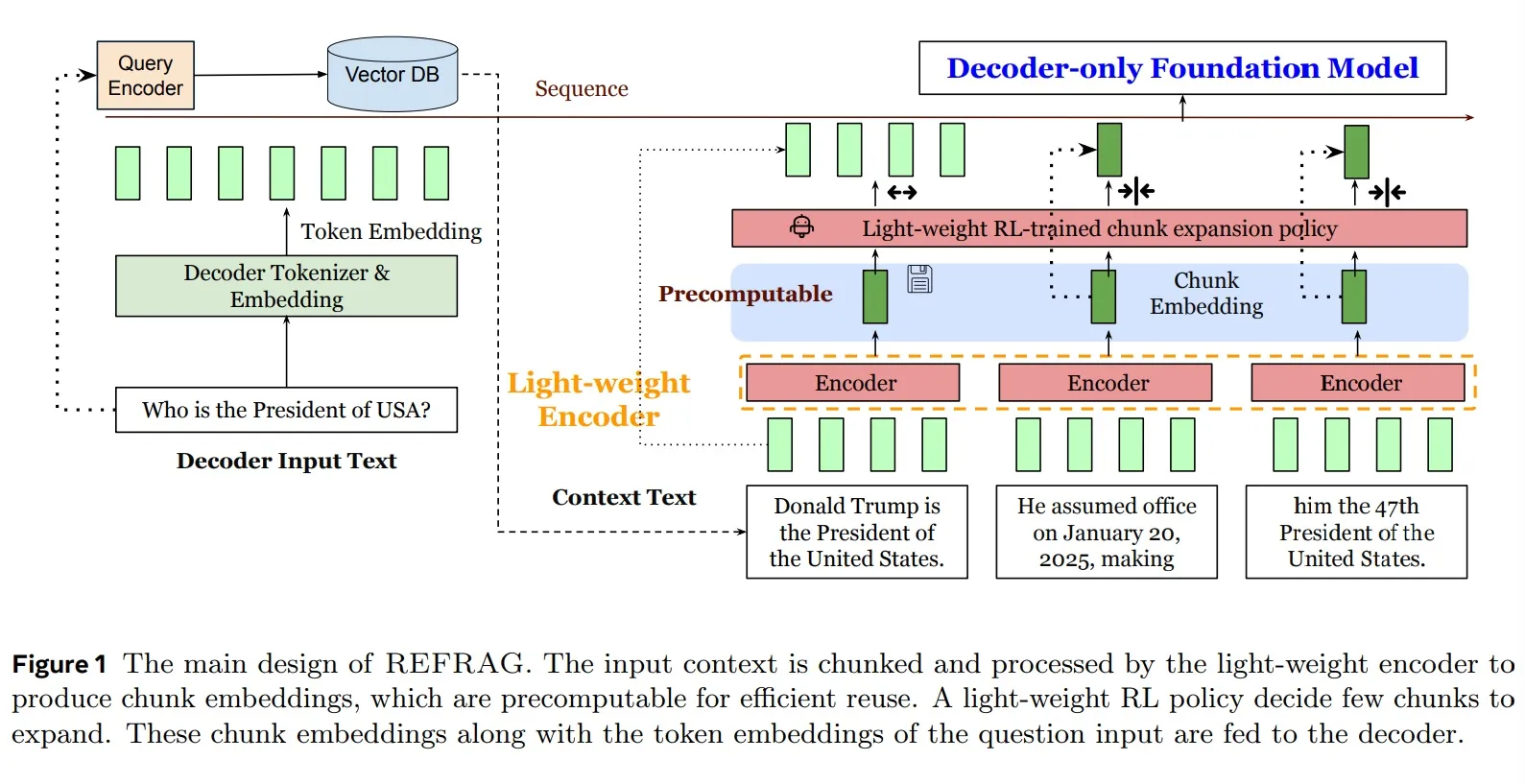
1. Compress
- A lightweight encoder turns long text into chunk embeddings.
- Input length shrinks from thousands of tokens to a few hundred vectors.
- Embeddings are cacheable, eliminating repeat compute.
2. Sense
- A reinforcement learning policy network evaluates which chunks are critical.
- Key passages are preserved as raw text.
3. Expand
- The final input is a hybrid sequence:
- Most content as compressed embeddings
- A handful of raw-text chunks for precise reasoning
This lets the LLM process far more context without drowning in redundant attention calculations.
The Numbers: Speed at Scale
REFRAG isn’t just theory. According to the paper:
- 30.85× faster TTFT vs. baseline
- 3.75× faster than prior SOTA methods
- No loss in perplexity or task accuracy (QA, summarization, etc.)
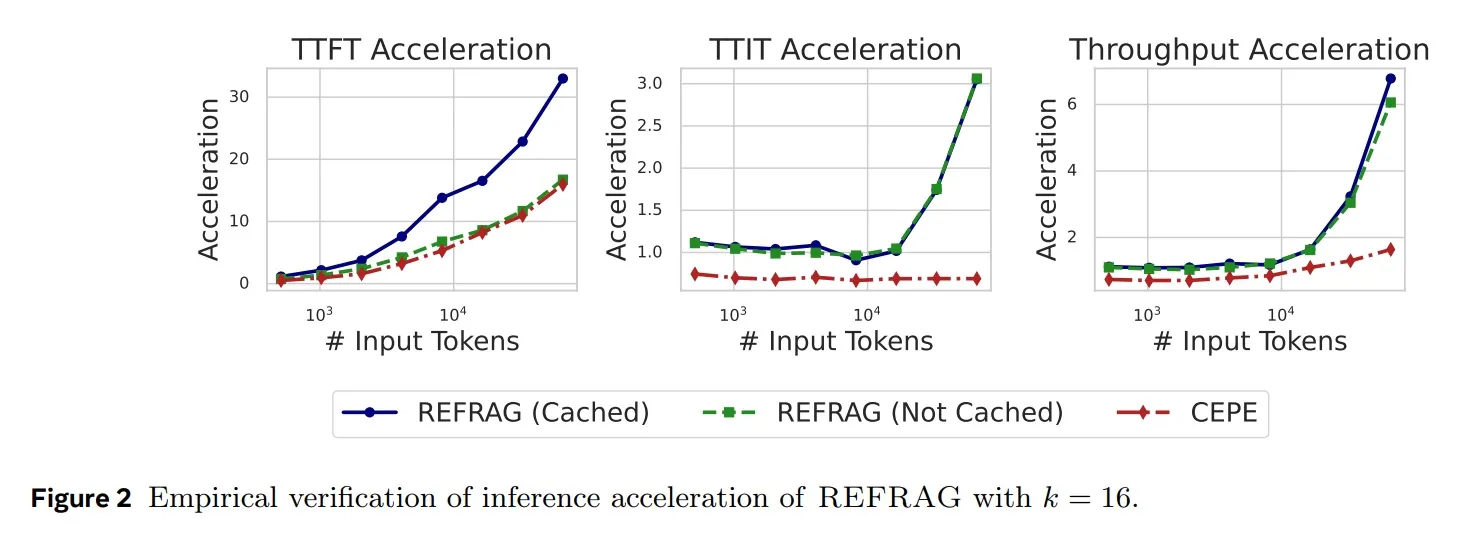
And because compression stretches compute budgets further, REFRAG effectively expands the usable context window 16×. That’s not just faster — it’s broader too.
Beyond RAG
While the framework was designed for RAG, its utility goes further.
- Multi-turn dialogue
- Long-document summarization
- Any task where context bloat is the bottleneck
REFRAG offers a path to faster, cheaper, and more scalable LLM applications.
As one Reddit commenter put it:
“If this really works as described, it’s a big win for RAG. Faster, bigger context, same accuracy — that’s game-changing.”
Why It Matters
Meta’s Superintelligence Lab has staked its first claim: efficiency, not just scale, will define the next wave of AI.
By surgically reducing wasted compute, REFRAG delivers on both speed and accuracy — two things usually at odds in long-context AI.
It’s an early but significant signal that the lab is aiming not just to build bigger models, but smarter architectures.
🔗 References:
- Paper: https://arxiv.org/abs/2509.01092
- Community discussion: Reddit thread