
Meta AI has introduced MobileLLM-R1, a groundbreaking series of efficient inference models, demonstrating remarkable performance gains—2-5x better than existing open-source alternatives—even with significantly less training data and fewer parameters.
Meta’s MobileLLM-R1 Ushers in a New Era for Small Parameter Models
Meta AI is pushing the boundaries of efficient language models with the recent release of MobileLLM-R1. This new family of models marks a significant advancement, proving that smaller parameter counts can achieve state-of-the-art results, challenging larger, more resource-intensive models.
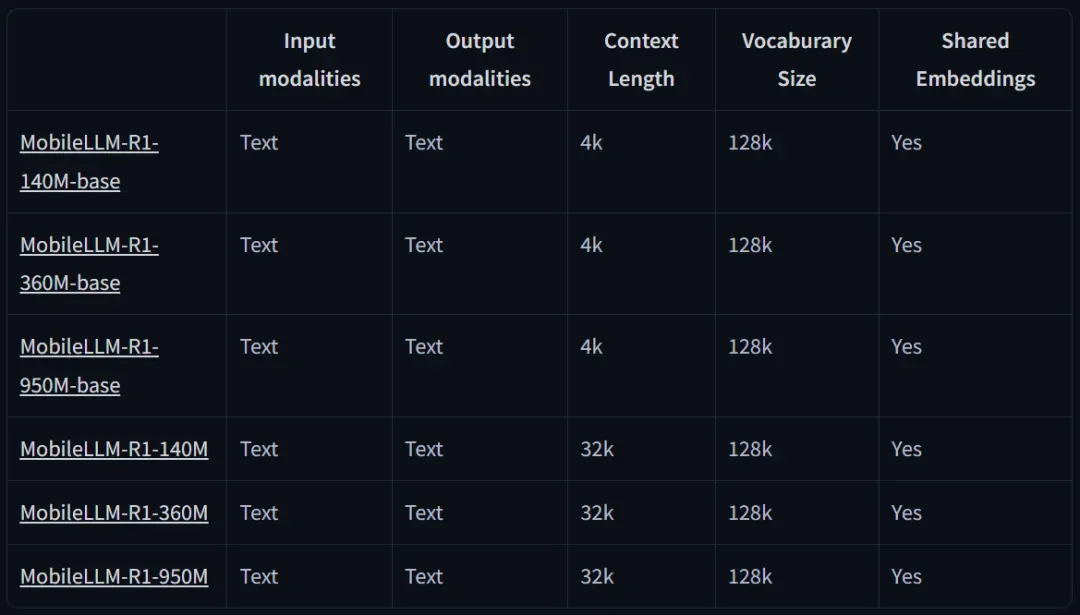
The MobileLLM-R1 series includes foundational models such as MobileLLM-R1-140M-base, MobileLLM-R1-360M-base, and MobileLLM-R1-950M-base, along with their fine-tuned counterparts. These are not general-purpose chatbots but are specifically supervised fine-tuned (SFT) for specialized tasks, excelling in mathematics, programming (Python, C++), and scientific problem-solving.
Meta has also provided the complete training methodology and datasets, promoting reproducibility and fostering further research within the community.
Unprecedented Efficiency: Outperforming Larger Models with Less
A key highlight is the MobileLLM-R1 950M model. Despite being pre-trained on approximately 2 trillion high-quality tokens and having a total training token count under 5 trillion, it achieves comparable or superior performance on benchmarks like MATH, GSM8K, MMLU, and LiveCodeBench when pitted against Qwen3 0.6B, which was trained on 36 trillion tokens.
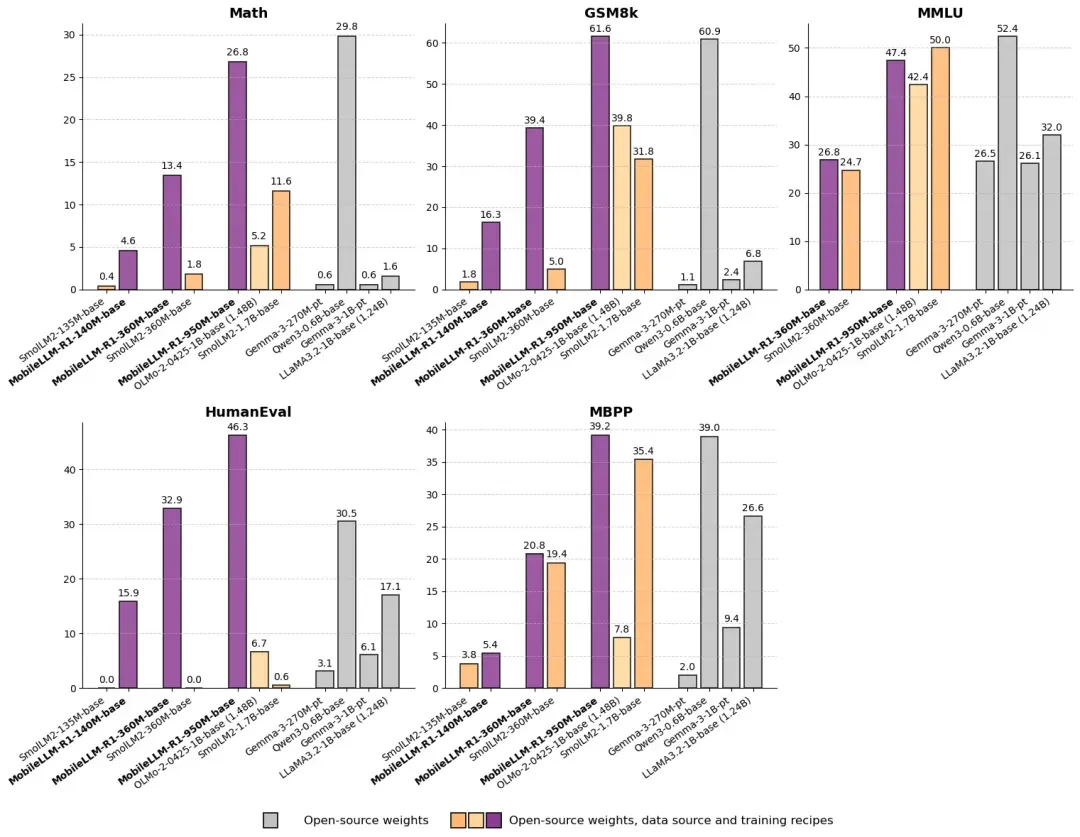
When compared to other fully open-source models, the MobileLLM-R1 950M model shows remarkable improvements. It achieves approximately five times higher accuracy on the MATH benchmark than Olmo 1.24B and about twice the accuracy of SmolLM2 1.7B. Furthermore, its performance on coding benchmarks significantly surpasses both Olmo 1.24B and SmolLM2 1.7B, setting a new benchmark for fully open-source models in this domain.
Token Efficiency and Performance Gains
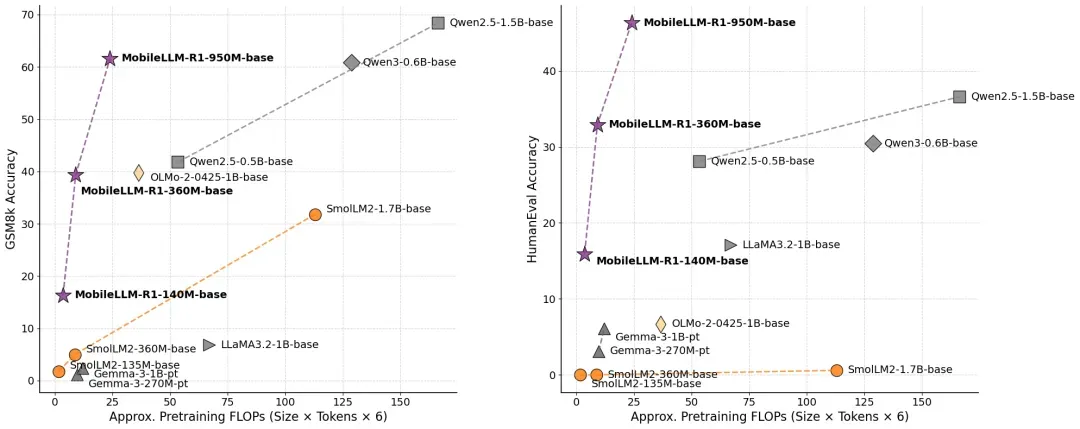
The efficiency of MobileLLM-R1 is further illustrated by its token efficiency compared to other models:
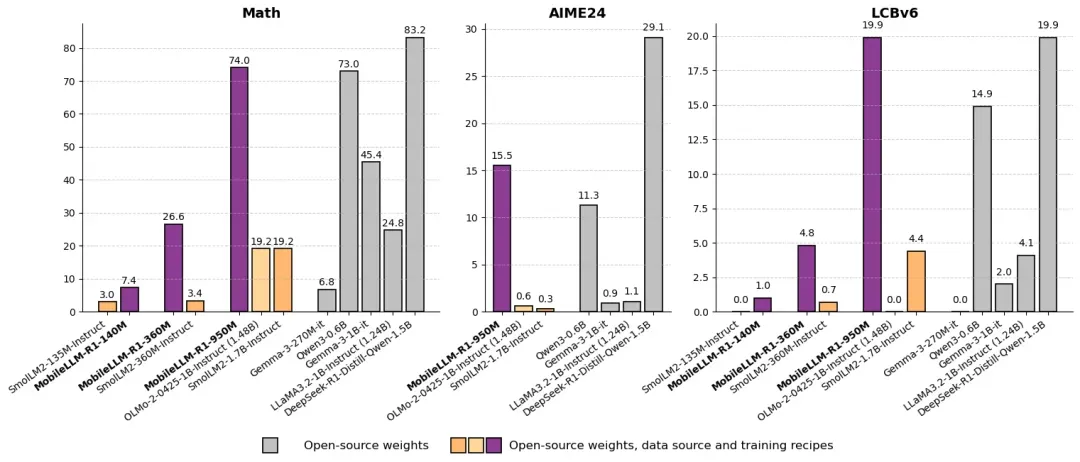
Post-training comparisons also highlight the model’s advanced capabilities:
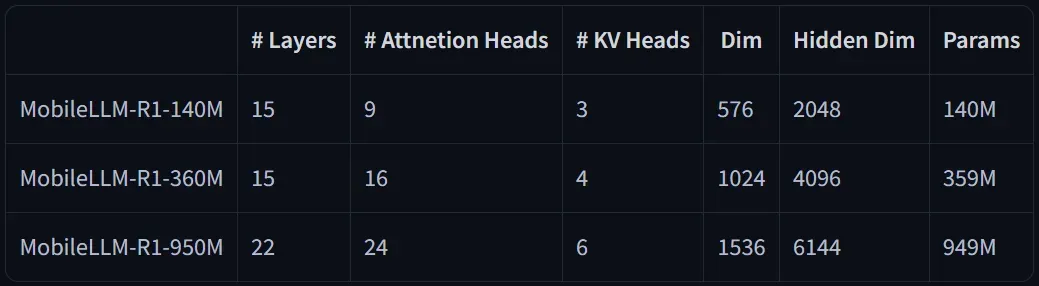
Architectural Innovations
The underlying architecture of the MobileLLM-R1 models is designed for optimal performance and efficiency:
Community Impact and Future Implications
The release of MobileLLM-R1 has generated considerable buzz within the machine learning community. Researchers and developers are welcoming explorations into smaller, highly efficient models by leading organizations like Alibaba (Tongyi Qianwen) and Meta. This trend is significant because:
- Lower Training Costs: Smaller models require considerably less computational resources for training, making advanced research more accessible.
- Rapid Iteration: Reduced training times allow for quicker experimentation with cutting-edge techniques from recent research papers.
- Wider Deployment: The decreased model size opens doors for deployment on a broader range of edge devices, enabling more widespread practical applications.
As training costs continue to decrease, we can anticipate the development of even more capable and accessible AI models.
The Minds Behind MobileLLM-R1
The talented team behind MobileLLM-R1, whose work has been in development for about a year, is spearheaded by leading researchers, with a notable contribution from Chinese researchers.
Zechun Liu

Zechun Liu is a Research Scientist at Meta AI, focusing on the efficient deployment and optimization of large and foundational models. Her research encompasses pre-training and post-training of large language models, neural network architecture design and search, quantization, pruning, sparsity, knowledge distillation, and efficient vision-language models. Her primary goal is to achieve high-performance model inference and deployment in resource-constrained environments.
Zechun earned her Bachelor’s degree from Fudan University in 2016. She was a visiting scholar at Carnegie Mellon University from 2019 to 2021, mentored by Professor Marios Savvides and Professor Eric Xing. In June 2021, she obtained her Ph.D. from the Hong Kong University of Science and Technology under the supervision of Professor Kwang-Ting Tim CHENG. Zechun has published over 20 papers in top-tier conferences and journals, garnering thousands of citations.
Ernie Chang

Ernie Chang is a Research Scientist at Meta AI, specializing in Natural Language Processing, multimodal learning, and efficient model deployment. He joined Meta in February 2023 and has contributed to several cutting-edge research projects.
Ernie has co-authored significant papers, including “Agent-as-a-Judge: Evaluate Agents with Agents,” which introduced a novel evaluation method using agent models to assess other agents, thereby improving evaluation efficiency and accuracy. He also contributed to the research on “MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases,” which focused on optimizing small language models for mobile device applications. Ernie’s research interests include multilingual processing and multimodal systems.
Changsheng Zhao

Changsheng Zhao is a Research Scientist at Meta AI, concentrating on Natural Language Processing, deep learning, and the efficient deployment and optimization of large language models. He completed his undergraduate studies at Peking University and pursued his Master’s degree at Columbia University. Following his studies, he worked as a researcher at Samsung AI Research America before joining Meta in 2021.

At Meta, Changsheng Zhao has been involved in numerous pioneering research initiatives, primarily in areas such as model quantization, neural network architectures, and multimodal systems. Some of his notable work includes:
- ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization: This work explores scaling laws in extremely low-bit quantization for large language models, aiming to balance model size and accuracy.
- Llama Guard 3-1B-INT4: He contributed to the development of a variant of Meta’s open-source Llama Guard model. This compact and efficient 1B parameter INT4 quantized version was open-sourced at Meta Connect 2024 and is designed for AI safety and content moderation.