
The Era of Intelligent Agents Demands Smarter Tools
In the burgeoning age of AI agents, tools are no longer mere wrappers around traditional APIs or functions. They are the critical enablers that dictate an agent’s ability to perform tasks efficiently and effectively. To truly unlock the potential of these agents, we must fundamentally rethink how we approach tool development. Unlike traditional software development, which relies on deterministic logic, AI agents are inherently non-deterministic. They can produce different outputs even with identical inputs, necessitating a new paradigm for designing the tools they use.
This paradigm shift isn’t just about how to build tools, but crucially, how to make them perform optimally. The power of an AI agent is directly proportional to the quality of the tools provided. But the pressing question remains: how can we ensure these tools operate at their peak efficiency?
A recent article from Anthropic offers a clear and actionable path forward.

Original Post: https://www.anthropic.com/engineering/writing-tools-for-agents
This comprehensive guide from Anthropic introduces performance-boosting techniques that have proven highly effective across various agentic AI systems.
By the end of this tutorial, you will be equipped to:
- Build and test tool prototypes.
- Create and run comprehensive evaluations.
- Collaborate with agents (like Claude Code) to automate performance improvements.
Defining Tools in the Age of AI Agents
In computing, a deterministic system consistently produces the same output for identical inputs. Conversely, non-deterministic systems, such as AI agents, may generate different responses even under the same initial conditions.
Traditional software development establishes contracts between deterministic systems. For example, a getWeather("NYC") function call will always return the weather for New York in precisely the same way, regardless of how many times it’s invoked.
Tools for Large Language Models (LLMs), however, represent a novel form of software, embodying a contract between deterministic systems and non-deterministic agents. Consider a user asking, “Should I bring an umbrella today?” An agent might invoke a weather tool, rely on its general knowledge, or even pose a clarifying question (e.g., “Which location?”). Agents can also hallucinate or misunderstand how to use a tool.
This means we must fundamentally rethink our approach to writing software for agents. Tools and Message Channel Protocol (MCP) servers shouldn’t be treated as ordinary functions or APIs; they need to be purpose-built for agents.
So, how do we design such tools?
How to Write Tools for Agents
The process begins with rapidly prototyping tools and testing them locally.
This is followed by comprehensive evaluation to measure the impact of subsequent changes.
Through collaboration with agents, you can continuously iterate on this evaluate-and-improve cycle until agents demonstrate robust performance on real-world tasks.
Building Prototypes
This tutorial uses a Claude-based agent as its example. When developing tools with Claude Code, it’s beneficial to provide Claude with relevant documentation, including dependencies like software libraries, APIs, or the MCP SDK.
Documentation suitable for LLM consumption is often available on official websites in an llms.txt format. You can also package tools within a local MCP server or a Desktop Extension (DXT) to test them directly within Claude Code or Claude Desktop.
To connect a local MCP server to Claude Code, run claude mcp add <name> <command> [args...]. For local MCP servers or DXTs with Claude Desktop, navigate to “Settings > Developer” or “Settings > Extensions,” respectively. Tools can also be tested programmatically by passing them directly into Anthropic API calls.
Crucially, self-testing is essential to identify any shortcomings.
Running Evaluations
Next, you need to evaluate the effectiveness of your tools. Evaluations can be structured in several parts, starting with generating evaluation tasks.
After completing an early prototype, Claude Code can help vet your tool and generate dozens of prompt-response pairs. These prompts should originate from realistic use cases and be based on actual data sources and services (e.g., internal knowledge bases, microservices). Avoid overly simplistic or superficial sandbox environments, as they fail to stress-test tools under sufficiently complex conditions.
High-quality evaluation tasks often require multiple tool calls, sometimes dozens.
What constitutes a good task evaluation? Consider these examples:
- “Schedule a meeting next week with Jane to discuss our latest Acme Corp project. Attach the notes from our last project planning meeting and book a conference room.”
- “Customer ID 9182 reports being charged three times for a single purchase. Find all relevant log entries and determine if any other customers were affected by the same issue.”
- “Customer Sarah Chen has just submitted a cancellation request for her order. Prepare a retention offer. Determine: (1) the reason for their departure; (2) which retention offer is most compelling; and (3) the risk factors we should consider before presenting the offer.”
Conversely, weaker tasks might look like:
- “Schedule a meeting next week with jane@acme.corp.”
- “Search payment logs for
purchase_completeandcustomer_id=9182.” - “Find cancellation requests for customer ID 45892.”
Each evaluation prompt should be paired with a verifiable response or outcome. Your validators can range from simple exact string comparisons between factual data and sampled responses to more sophisticated prompts asking an LLM to judge the response. Avoid overly strict validators that might reject correct responses due to minor discrepancies in formatting, punctuation, or valid alternative phrasing.
For each prompt-response pair, you can optionally specify the tools the agent should use to solve the task, measuring whether the agent successfully learned to utilize each tool during the evaluation. However, since multiple valid approaches may exist to solve a task correctly, avoid over-specifying or overfitting strategies.
Next, run the evaluation. Programmatic execution via direct LLM API calls is recommended. A simple agent loop (e.g., alternating LLM API calls and tool invocations within a while loop) can be employed, with each evaluation task corresponding to one loop. Each evaluation agent should be assigned a task prompt and relevant tools.
If using Claude for evaluation, enable interleaved thinking to gain insight into why an agent might call or not call certain tools.
Beyond accuracy, consider collecting other metrics during evaluation:
- Total execution time for single tool calls and the overall task.
- Total number of tool invocations.
- Total token consumption.
- Tool error occurrences.
Analyzing Results
Often, what an agent omits from its feedback and responses is more significant than what it includes. LLMs don’t always accurately articulate their internal reasoning. Observe where agents get stuck or confused to pinpoint weaknesses in your tools based on feedback. Concurrently, review the raw conversation logs (including tool calls and responses) to capture behaviors not explicitly articulated in the agent’s Chain-of-Thought (CoT). Remember, evaluation agents don’t necessarily “know” the correct answer or optimal strategy.
Additionally, analyze your tool call metrics:
- Excessive redundant calls: May indicate a need to redesign pagination or token limit parameters.
- Too many errors due to invalid parameters: Might suggest the tool requires clearer descriptions or better usage examples.
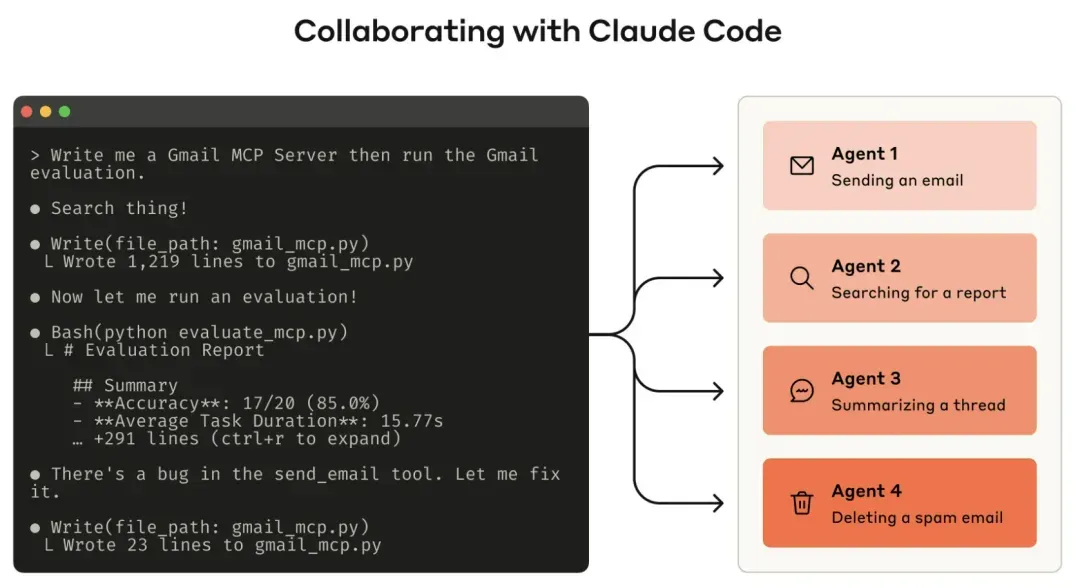
Users can even collaborate with the agent to analyze results and improve tools. Simply concatenate the conversation logs of an evaluation agent and paste them into Claude Code. Claude excels at analyzing conversation logs and can refactor tools in bulk.
Principles for Writing Effective Tools
Choose Tools Wisely
More tools don’t automatically equate to better outcomes. We’ve observed that tools simply wrapping existing software functionality or APIs may not always be suitable for agents. This is because agents possess different affordances than traditional software; they perceive and utilize tools in fundamentally distinct ways.
For instance, LLM agents have limited context windows. While computer memory is cheap and virtually infinite, an agent might struggle if a tool returns all contacts from an address book and must be read token by token, wasting its limited context on irrelevant information. A more natural approach, for both agents and humans, is to directly jump to relevant sections (e.g., by alphabetical order).
Therefore, it’s advisable to build a small number of well-considered tools for high-value workflows, aligned with evaluation tasks, before expanding. Instead of a list_contacts tool, implement Contactss or message_contact.
Furthermore, tools have compositional capabilities, allowing them to handle multiple discrete operations (or API calls) concurrently under the hood. Tools can:
- Attach relevant metadata when returning results.
- Perform multi-step tasks that are often chained together in a single invocation.
Examples of compositional features:
- Instead of separate
list_users,list_events, andcreate_eventtools, implement aschedule_eventtool that finds free time slots and directly schedules events. - Instead of a
read_logstool, implementsearch_logsthat returns only relevant log lines with necessary context. - Instead of
get_customer_by_id,list_transactions, andlist_notestools, implement aget_customer_contexttool that aggregates all recent and relevant information for a customer in one call.
Each tool you build should have a clear, singular purpose. Tools should empower agents to decompose and solve tasks, much like humans, by accessing the same underlying resources while reducing the contextual space that would otherwise be consumed by intermediate results. Overlapping or redundant tools can distract agents and hinder their ability to select efficient strategies. Therefore, prudent and selective planning of which tools to build (or not build) often yields greater returns.
Implement Namespacing for Tools
AI agents may interface with dozens of MCP servers and hundreds of tools, including those developed by others. When tools have overlapping functionality or ambiguous purposes, agents can become confused about which tool to use. Namespacing—grouping related tools under a common prefix—can delineate boundaries between different tools; some MCP clients adopt this by default.
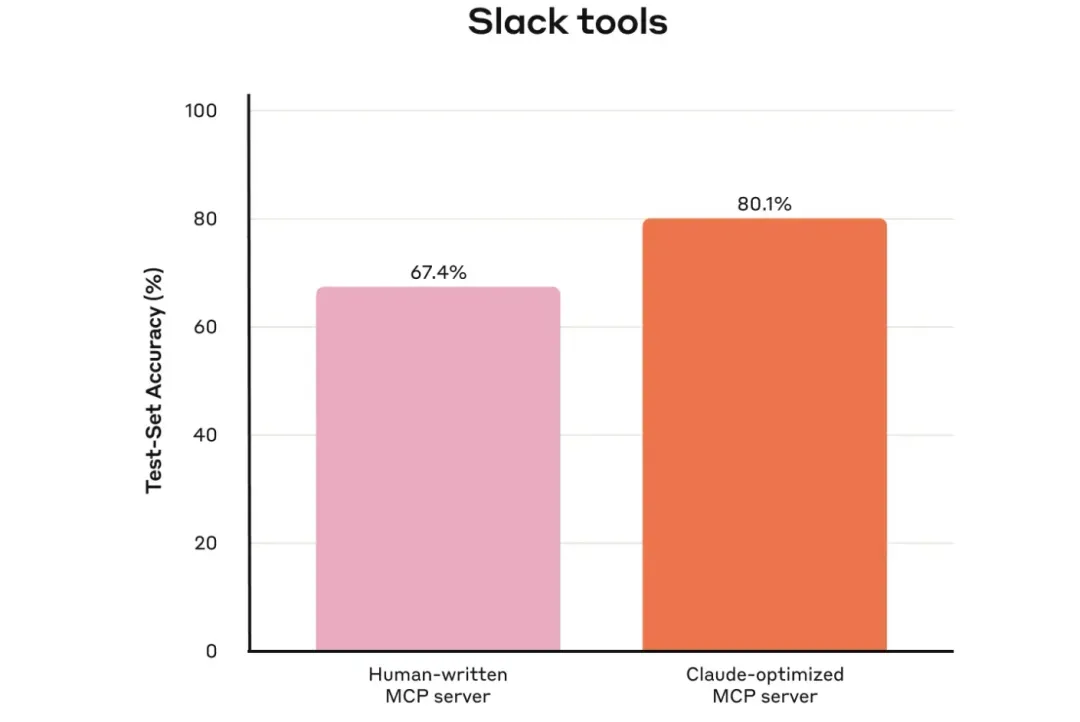
For example, namespace by service (e.g., asana_search, jira_search) or by resource (e.g., asana_projects_search, asana_users_search) to help agents select the correct tool at the appropriate time. Prefix versus suffix naming has shown different effects in tool usage evaluations. It’s recommended to choose a naming convention based on your evaluation results.
Failure to do so can lead to:
- Calling the wrong tool.
- Calling the correct tool with incorrect parameters.
- Invoking too few tools.
- Incorrectly handling tool responses.
Return Meaningful Context from Tools
Similarly, tool implementations should focus on returning high-signal information to the agent. Prioritize contextual relevance over flexibility and avoid low-level technical identifiers (e.g., uuid, 256px_image_url, mime_type). Fields like name, image_url, and file_type are more likely to directly influence an agent’s downstream operations and responses.
Agents’ ability to process natural language names, terms, or identifiers significantly outweighs their ability to handle obscure ones. In practice, simply parsing arbitrary alphanumeric UUIDs into semantically meaningful and interpretable language (even zero-indexed ID schemes) has demonstrably improved Claude’s accuracy in retrieval tasks, reducing hallucinations.
In some cases, agents may need flexibility to interact with both natural language and technical identifier outputs, even if just to trigger downstream tool calls (e.g., search_user(name='jane') → send_message(id=12345)). You can enable both capabilities by exposing a simple response_format enum parameter within the tool, allowing the agent to control whether the tool returns “concise” or “detailed” responses.
enum ResponseFormat {
DETAILED = "detailed",
CONCISE = "concise"
}Here’s an example of an enum to control tool response verbosity:
Here’s an example of a detailed tool response (206 tokens):
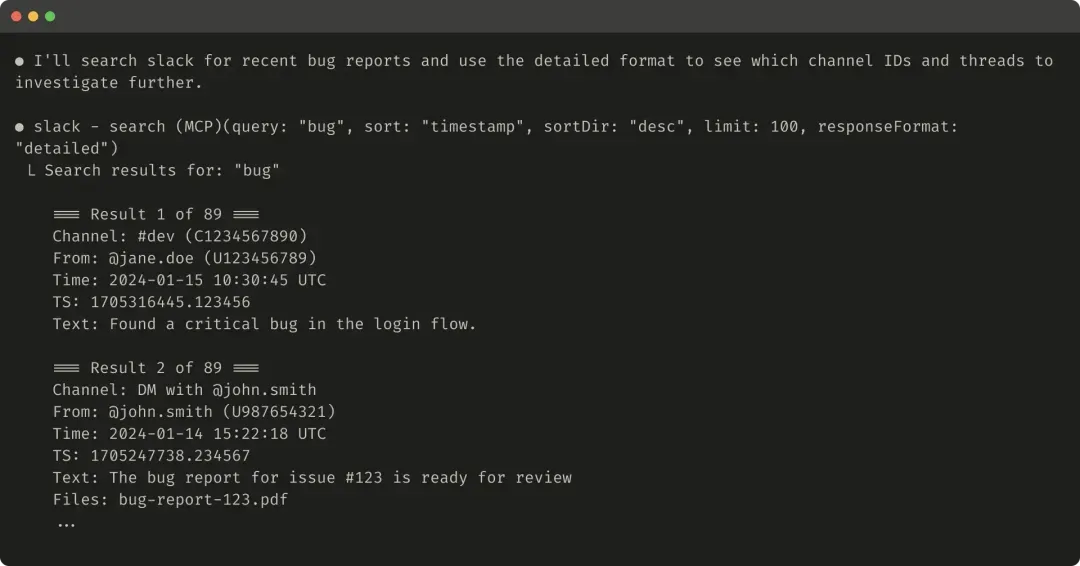
Here’s an example of a concise tool response (72 tokens):
Slack threads and replies are identified by a unique thread_ts, which is necessary for fetching thread replies. thread_ts, along with other IDs (channel_id, user_id), can be retrieved from a “detailed” tool response for subsequent tool calls requiring these IDs. A “concise” tool response returns only the thread content, omitting the IDs. This example uses approximately one-third of the tokens for the “concise” response.
Your tool response structure (e.g., XML, JSON, or Markdown) also impacts evaluation performance. There’s no one-size-fits-all solution, as LLMs are trained on next-token prediction and tend to perform best with formats matching their training data. The optimal response structure varies by task and agent, so it’s recommended to choose based on your own evaluations.
Optimize Tool Responses for Token Efficiency
Optimizing context quality is paramount. Equally important is optimizing the quantity of context returned to the agent within tool responses. Anthropic recommends combining pagination, range selection, filtering, and/or truncation for any tool response that might consume significant context, with sensible default parameter values. For Claude Code, tool response limits default to 25,000 tokens. While effective context lengths for agents will grow over time, the need for context-efficient tools will persist.
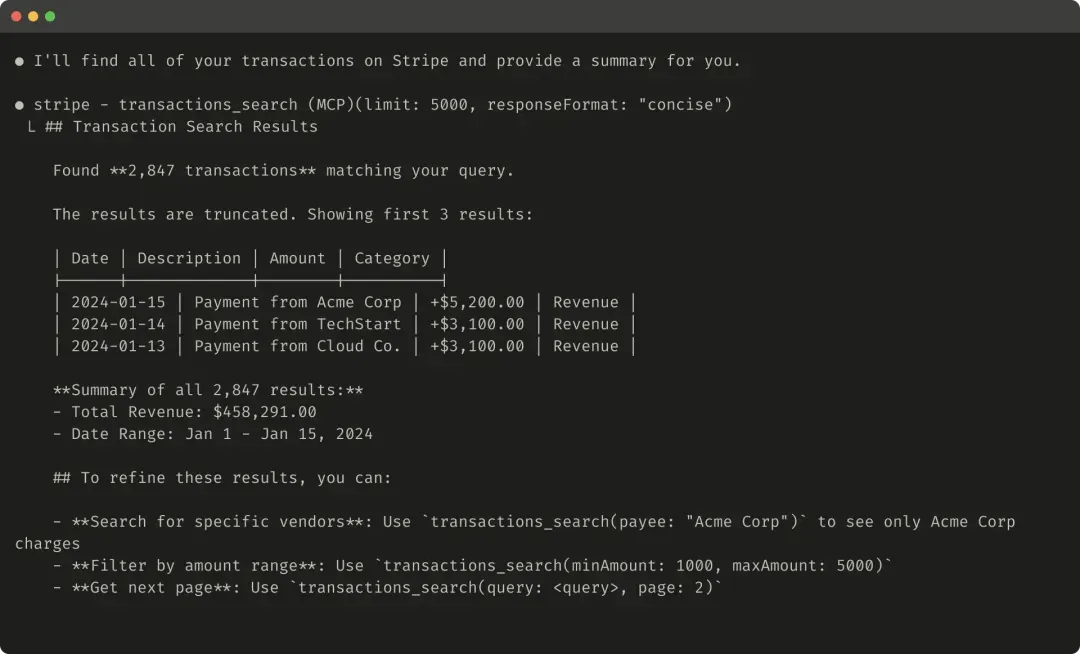
If you choose to truncate responses, provide practical guidance to the agent. Directly encourage more token-efficient strategies, such as multiple small, targeted searches in knowledge retrieval tasks rather than a single, broad search. Similarly, if tool calls trigger errors (e.g., during input validation), design error responses to clearly communicate specific, actionable improvements rather than obscure error codes or tracebacks.
Here’s an example of a truncated tool response:
Here’s an example of a useless error response:
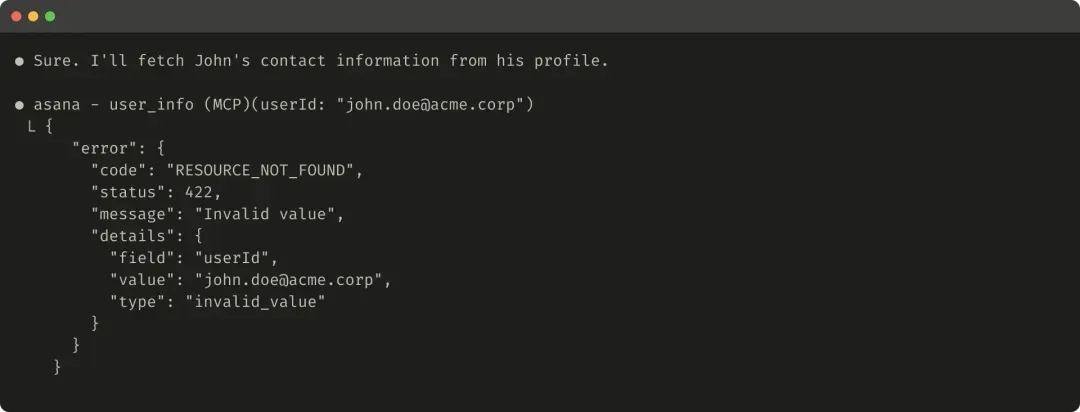
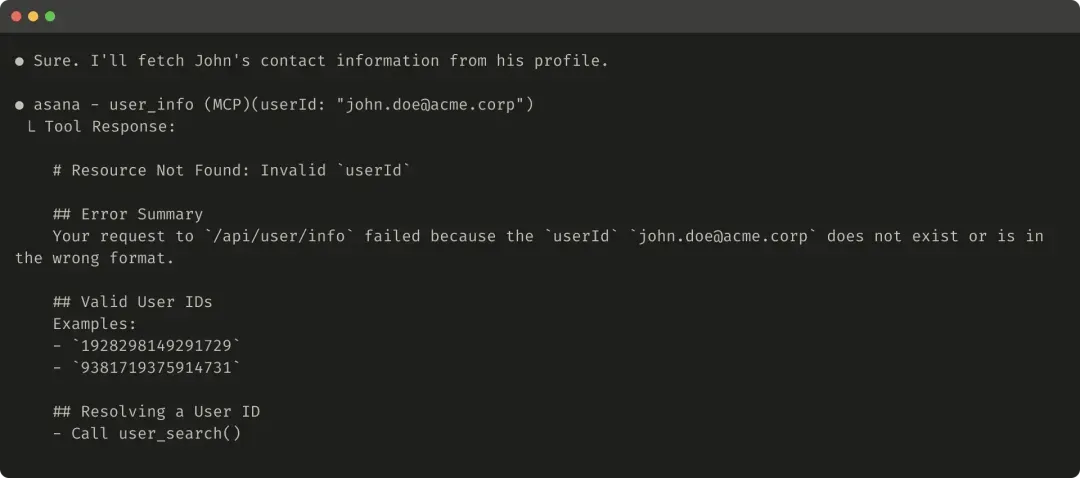
Here’s an example of a helpful error response:
Rapidly Build Tool Descriptions
One of the most effective methods for improving tools is rapidly building tool descriptions and specifications. As these are loaded into the agent’s context, they collectively guide the agent toward effective tool invocation behavior. When writing descriptions, think about how you’d explain your tool to a new team member. Consider implicitly introduced context—specific query formats, definitions of jargon, relationships between underlying resources—and make them explicit. Avoid ambiguity by clearly describing (and enforcing with strict data models) the expected inputs and outputs. Specifically, the naming of input parameters should be clear and unambiguous: use user_id rather than user.
Through evaluation, you can measure the impact of rapid building with confidence. Even minor improvements to tool descriptions can lead to significant gains. After precise improvements to tool descriptions, Claude Sonnet 3.5 achieved state-of-the-art performance on the SWE-bench Verified evaluation, drastically reducing error rates and increasing task completion.
Looking Ahead
To build effective agent tools, we must recalibrate software development practices, shifting from predictable deterministic patterns to non-deterministic ones. Through the iterative, evaluation-driven process described here, consistent patterns for tool success are emerging: effective tools should have clear, unambiguous definitions, make reasonable use of agent context, be composable across different workflows, and enable agents to intuitively solve real-world tasks.
Anthropic anticipates that the specific mechanisms through which agents interact with the world will continue to evolve—from updates to the MCP protocol to upgrades in the underlying LLMs themselves. By employing a systematic, evaluation-driven approach to agent tool improvement, we can ensure that as agent capabilities advance, the tools they rely on evolve in tandem.