
TL;DR
LoRA (Low-Rank Adaptation) can match the sample efficiency and final performance of full fine-tuning — but only if you use it correctly. The paper LoRA Without Regret (Schulman et al., 2025) shows:
- Apply LoRA to all layers, especially the MLP/MoE blocks.
- LoRA’s optimal learning rate ≈ 10× FullFT’s LR (≈15× in very short runs).
- LoRA is less tolerant to large batch sizes than FullFT.
- In reinforcement learning, even rank-1 LoRA can match FullFT.
- LoRA capacity matters: once the adapter rank runs out of space, learning curves diverge from FullFT.
Why This Matters
Large language models are enormous. Modern base models like Llama-3 or Qwen-3 have tens or hundreds of billions of parameters, sometimes scaling into the trillion range. Full fine-tuning (FullFT) requires updating all weights and optimizer states, which is both memory-hungry and slow.
LoRA offers a different tradeoff: freeze the massive base model, and train only a low-rank correction. This reduces the number of trainable parameters by orders of magnitude and makes serving multiple fine-tuned variants feasible.
But the key question remained: can LoRA actually match FullFT in performance, or is it always a compromise?
Thinking Machines’ work provides the clearest empirical answer so far.
Background: LoRA in One Equation

Instead of updating (W), LoRA learns only (A) and (B), which contain far fewer parameters.
Introduced by Hu et al. (2021), LoRA quickly became the dominant parameter-efficient fine-tuning (PEFT) method, spawning variants such as QLoRA (Dettmers et al., 2023) for 4-bit quantization.
Key Findings from LoRA Without Regret
1. Rank Matters: Capacity and Divergence
Thinking Machines ran supervised fine-tuning experiments on datasets like Tulu-3 and subsets of OpenThoughts-3.
- High-rank LoRA (e.g., r=256) tracks FullFT almost perfectly.
- Low-rank LoRA (e.g., r=4, 16) initially follows the FullFT loss curve, but after a certain threshold, the curve diverges — indicating the adapter “runs out of capacity.”
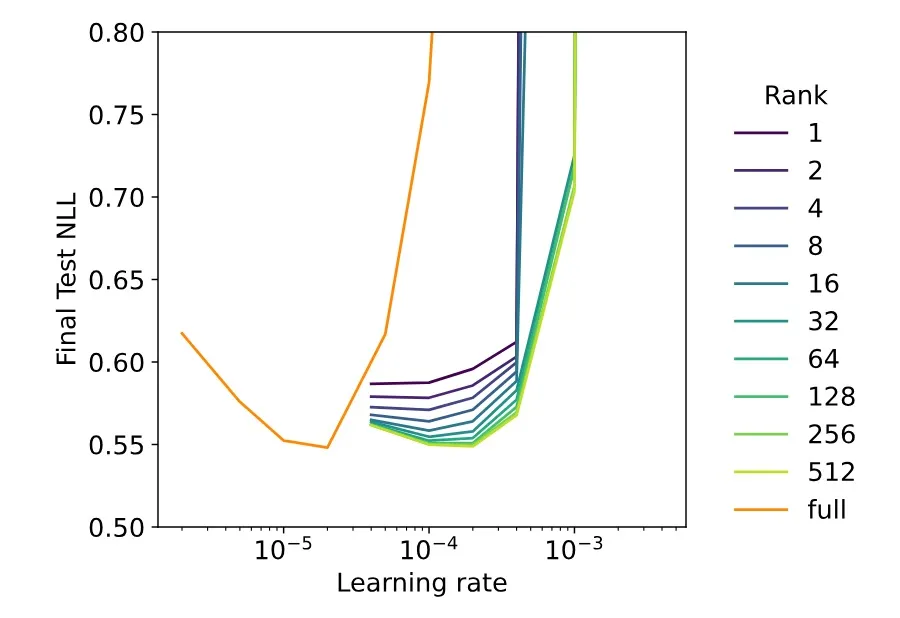
Figure 1. Training loss vs steps for FullFT (black solid) vs LoRA ranks (colored dashed). High-rank adapters remain close; low ranks deviate after a capacity threshold.
2. The 10× Learning Rate Rule
Perhaps the most striking empirical law:
- Across both supervised and reinforcement learning experiments, LoRA’s optimal learning rate ≈ 10× that of FullFT.
- For very short training (≤100 steps), LoRA may even prefer ~15× FullFT’s LR.
Why?
- At initialization, (B) is zero. Early updates to (A) have almost no effect until (B) grows.
- This delays effective learning, so LoRA benefits from a higher LR to compensate.
- Over time, the effect stabilizes around ~10×.
Figure 2. Validation loss vs learning rate (U-shaped curve). LoRA’s curve minimum lies about one order of magnitude to the right of FullFT’s.
3. Batch Size Sensitivity
LoRA and FullFT behave differently as batch size grows:
- At small batches (e.g., 32), LoRA and FullFT converge to similar performance.
- At large batches (e.g., 1024+), LoRA consistently underperforms FullFT — even at high rank.
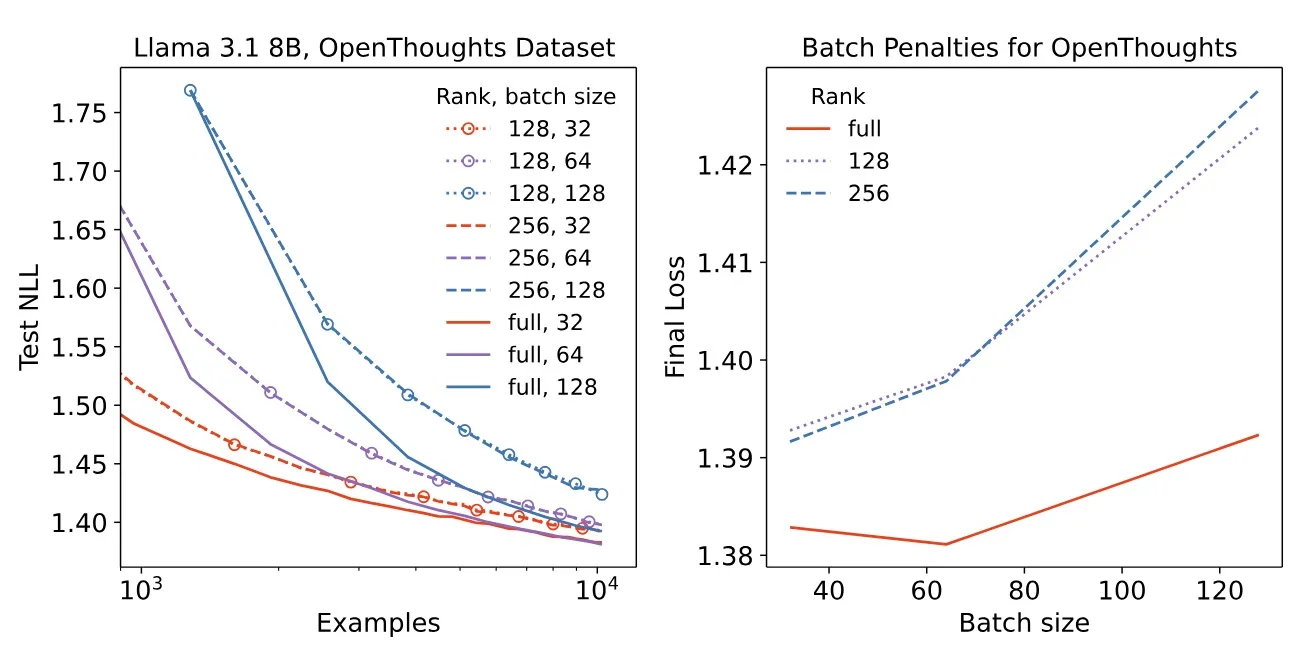 Figure 3. Final validation loss vs batch size. LoRA (dashed) increasingly lags behind FullFT (solid) as batch size grows.
Figure 3. Final validation loss vs batch size. LoRA (dashed) increasingly lags behind FullFT (solid) as batch size grows.
4. Where to Apply LoRA: Layers Matter
LoRA can be applied to attention projections (Q, K, V, O) and/or MLP blocks.
Findings:
- MLP (and MoE) layers yield much stronger benefits than attention-only LoRA.
- Attention-only LoRA underperforms MLP-only, even at similar parameter counts.
- Best results come from applying LoRA to all major weight matrices.
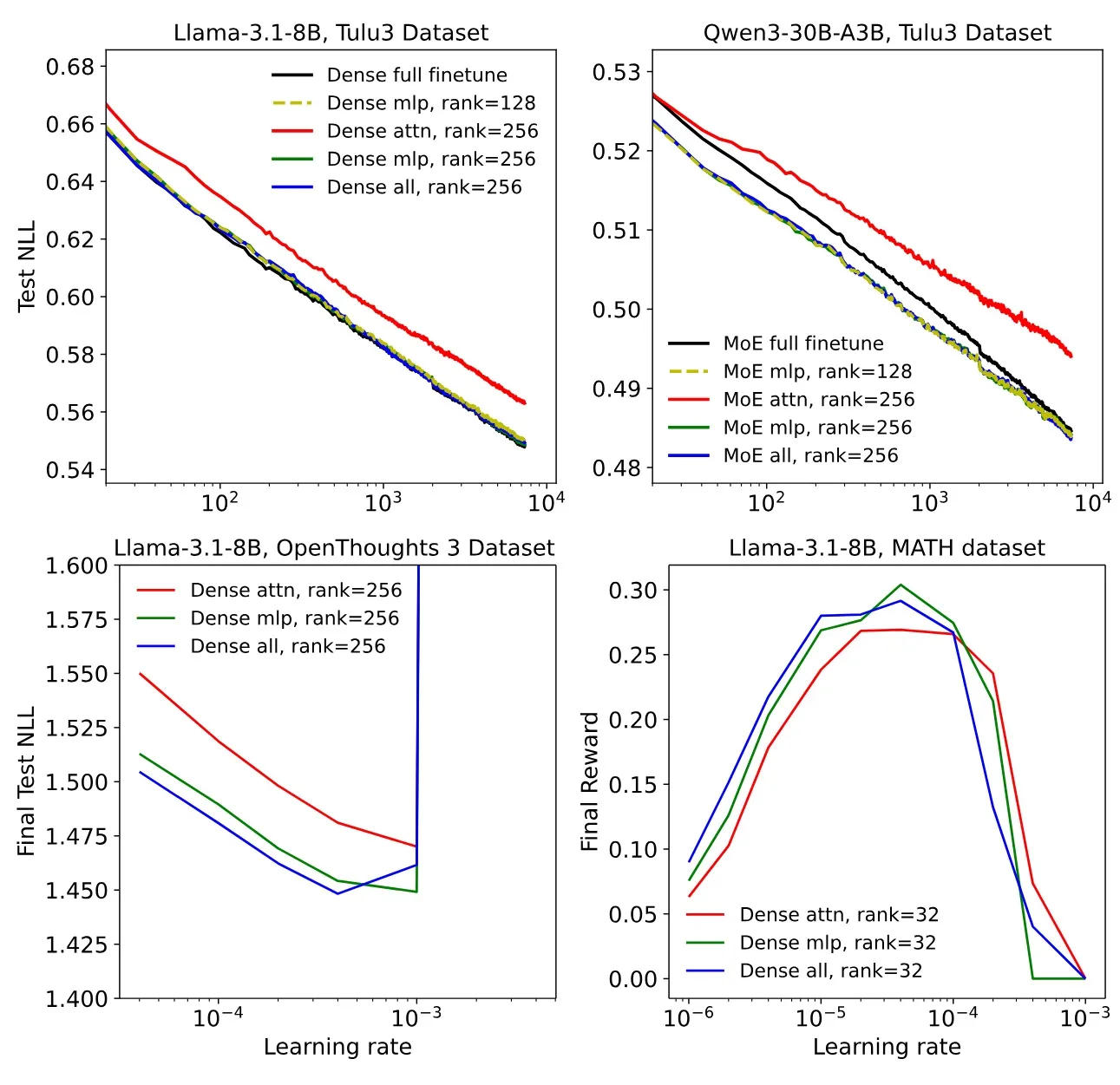 Figure 4. Performance comparison of LoRA placement: MLP-only > attention-only; all-layers LoRA ≈ FullFT.
Figure 4. Performance comparison of LoRA placement: MLP-only > attention-only; all-layers LoRA ≈ FullFT.
5. Reinforcement Learning: LoRA Shines
In reinforcement learning with policy-gradient updates (datasets: MATH, GSM, DeepMath):
- Even rank-1 LoRA matched FullFT’s performance.
- LoRA exhibited a wider effective LR range, making hyperparameter tuning easier.
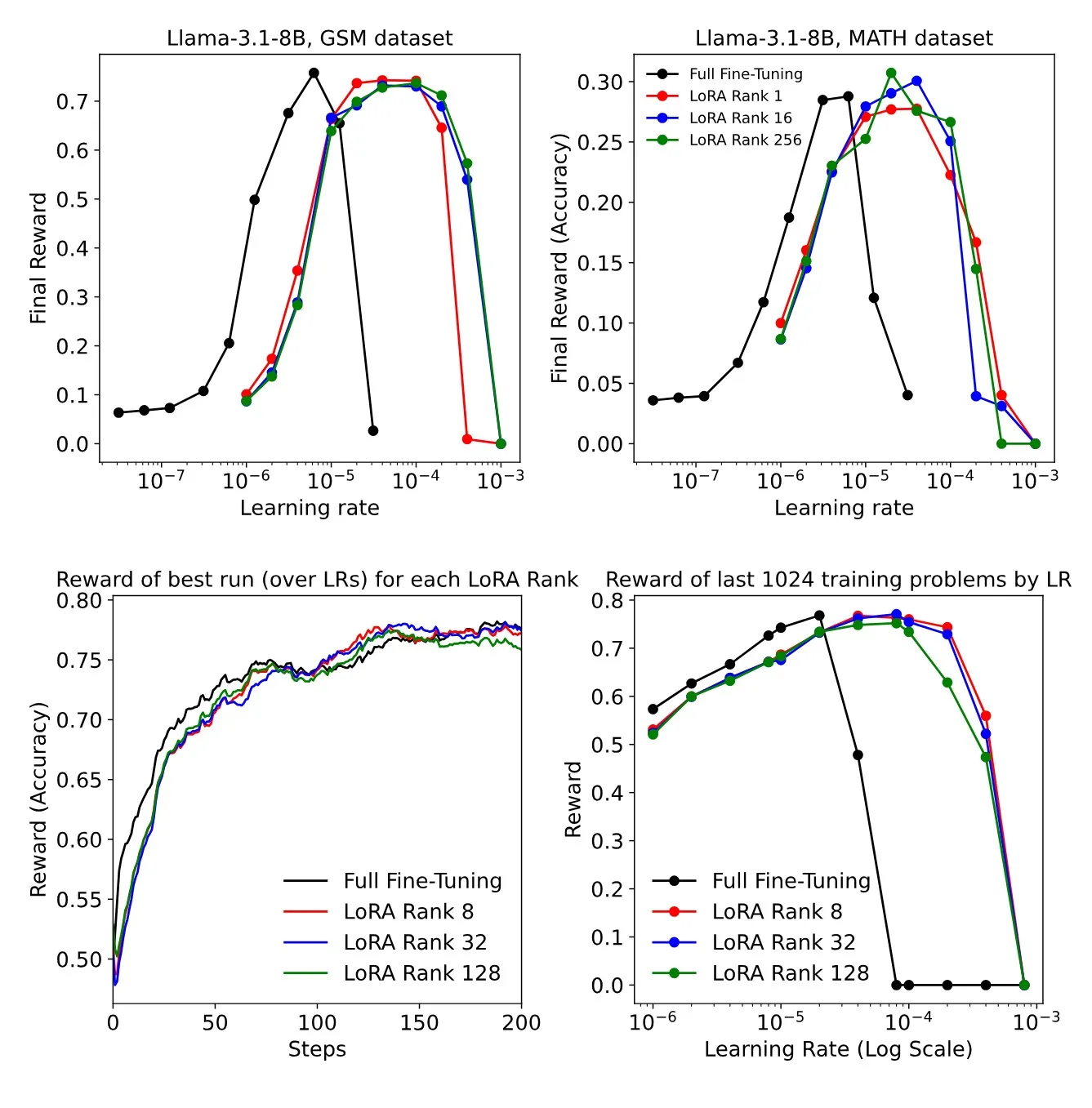 Figure 5. Reward vs steps for FullFT (solid black) vs LoRA ranks (colored). All LoRA ranks reach similar peak reward.
Figure 5. Reward vs steps for FullFT (solid black) vs LoRA ranks (colored). All LoRA ranks reach similar peak reward.
6. A Predictive Formula for Optimal LR
The authors fitted a function relating optimal LR to:
- Hidden dimension size.
- Model family (Llama vs Qwen).
This gives practitioners a way to estimate optimal LoRA LR without full sweeps.
Takeaway: In practice, though, the “×10 heuristic” is robust enough as a starting point.
Practical Recipe for Engineers
Here’s a consolidated engineering checklist drawn from the paper:
| Hyperparameter | Recommendation | Notes |
|---|---|---|
| Learning rate | Start with FullFT_LR × 10 | For short runs (≤100 steps), consider ×15 |
| Rank (r) | Sweep 256 | Choose based on dataset complexity; higher = safer |
| Scaling α | 32 | As in paper; effective scale = α / r |
| Target modules | MLP/MoE (gate, up, down) + attention (q, v) | Attention-only insufficient |
| Batch size | Prefer small/moderate (<512) | Large batch hurts LoRA more |
| RL fine-tuning | Even rank=1 is viable | Wider effective LR range |
A Minimal Reproducible Experiment
Below is a minimal Hugging Face + PEFT setup, reflecting the paper’s settings. Swap in your dataset and adjust hyperparameters.
# pip install transformers accelerate peft datasets
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model
import torch
model_name = "meta-llama/Llama-3.1-8b" # example base model
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
# LoRA config
lora_cfg = LoraConfig(
r=64, # try sweep: [4,16,64,256]
lora_alpha=32, # scaling factor
target_modules=["q_proj","v_proj","gate_proj","up_proj","down_proj"],
lora_dropout=0.0,
bias="none"
)
model = get_peft_model(model, lora_cfg)
# Training setup
fullft_lr = 1e-5
lora_lr = fullft_lr * 10
args = TrainingArguments(
per_device_train_batch_size=32,
gradient_accumulation_steps=1,
learning_rate=lora_lr,
warmup_steps=0,
num_train_epochs=3,
logging_steps=10,
save_strategy="epoch",
bf16=True,
optim="adamw_torch"
)
# dataset = load_dataset("tulu3", split="train[:1%]") # placeholder
# trainer = Trainer(model=model, args=args, train_dataset=dataset, tokenizer=tokenizer)
# trainer.train()Limitations and Open Questions
-
Data regime: When fine-tuning on datasets that approach pre-training scale, LoRA capacity becomes limiting (Biderman et al., 2024). FullFT may be unavoidable.
-
Batch size issue: Why LoRA fails at large batch remains unsolved. It may require modified optimizers or initialization schemes.
-
Theory gap: The 10× LR law has no formal derivation yet — it’s a robust empirical fact awaiting theoretical explanation.
-
Variants: Methods like LoRA+ (separate learning rates for A and B) or QLoRA may improve robustness further.
Takeaways
-
LoRA, correctly applied, is not a compromise — it can match FullFT in most post-training settings.
-
Two essential conditions: (1) apply to all layers (especially MLP/MoE), (2) ensure rank is high enough for dataset capacity.
-
Remember the 10× learning rate rule — this is the single most useful heuristic.
-
LoRA is batch-sensitive: watch out for very large batch sizes.
-
In reinforcement learning, even tiny ranks work astonishingly well.
References
-
Schulman, J., Thinking Machines et al. (2025). LoRA Without Regret. Thinking Machines Blog. https://thinkingmachines.ai/blog/lora/
-
Hu, E. J., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685.
-
Dettmers, T., et al. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314.
-
Biderman, S., et al. (2024). LoRA Learns Less and Forgets Less. arXiv:2405.16269.