
AI startup Anthropic has agreed to pay $1.5 billion to settle a class-action lawsuit filed by a group of authors. The lawsuit accused Anthropic of illegally pirating their works to train its chatbot, Claude.
A Landmark Copyright Settlement
If approved, the settlement would mark one of the largest copyright payouts in U.S. history and a pivotal moment in the ongoing conflict between AI companies and creative professionals, including writers and visual artists.
The agreement covers around 500,000 works, with each author expected to receive approximately $3,000 per book or work. As part of the settlement, Anthropic has also committed to destroying all pirated files and copies.
How It All Began
In August 2024, authors Andrea Bartz, Charles Graeber, and Kirk Wallace Johnson—alongside others—filed the lawsuit, claiming Anthropic knowingly used pirated books from sites like Library Genesis and Pirate Library Mirror. Court rulings revealed Anthropic had downloaded over 7 million pirated e-books, fully aware of their illegal status.
Initially, the Authors Guild estimated compensation at $750 per work, but the amount later increased to $3,000, likely after excluding duplicates and works not under copyright protection.
Anthropic’s Defense — and Why It Failed
Anthropic argued that training its AI models on copyrighted works should qualify as “fair use”, since AI-generated outputs are “transformative.”
However, critics pointed out that Anthropic wasn’t just using copyrighted works—it was using pirated content, making its defense untenable.
Industry Impact and Reactions
Authors Guild CEO Mary Rasenberger welcomed the outcome, stating it sends a strong message to the AI industry:
“Pirating authors’ works to train AI will have serious consequences.”
Yet some argue the deal favors tech companies more than writers. Despite the $1.5 billion payout, Anthropic recently raised $13 billion in new funding and reached a valuation of $183 billion, with annualized revenue surpassing $5 billion. For the company, the settlement may feel like a cost of doing business rather than a true penalty.
This aligns with a common tech industry playbook: scale first, pay fines later.
A Wider Wave of Copyright Battles
Anthropic’s settlement comes as other lawsuits against AI companies escalate:
- Apple is facing litigation from authors for allegedly using books in AI training.
- Warner Bros. sued Midjourney for generating images based on characters like Superman, Batman, Bugs Bunny, and Rick and Morty.
- Earlier this year, Disney and Universal also filed claims against Midjourney, accusing it of freeloading on their films and shows.
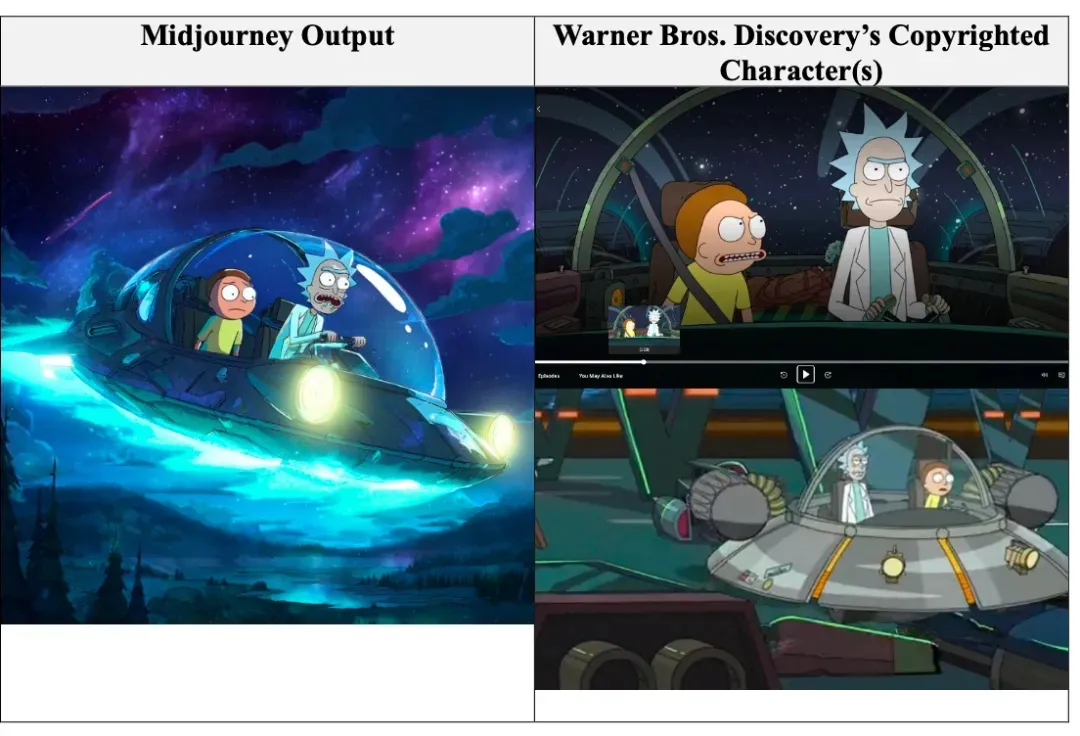
Left: Midjourney’s output of Rick and Morty; Right: Original still. Source: Hollywood Reporter
Heated Online Debate
The settlement has triggered intense online discussions:
- Some note Anthropic did not admit guilt, only agreed to a settlement. This leaves unresolved questions about whether training AI on copyrighted text is truly fair use.
- Others argue the case is actually a win for generative AI, as it sets a precedent suggesting text-based training itself is not direct infringement.



Discussions also highlight a darker angle: the practice of destructive book scanning. People can buy cheap second-hand books, slice off the spines, and scan them page by page. Some believe Anthropic may have relied on such methods, raising concerns about waste and irreversible damage to physical books.

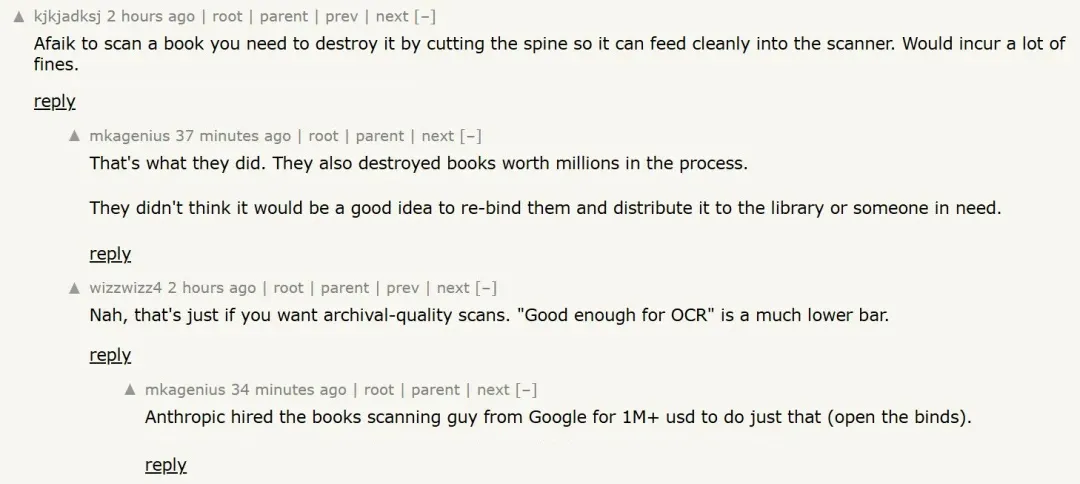
This recalls the New York Times’ lawsuit against OpenAI and Microsoft, which accused them of using millions of articles without authorization to train ChatGPT and Copilot.

What Comes Next
While Anthropic hasn’t admitted wrongdoing, it has chosen to pay the largest copyright settlement in history—backed by its massive war chest from recent funding.
Now, attention turns to OpenAI, Google, and other AI giants, who may soon face similar financial reckonings.

So the question remains:
Is training AI on copyrighted works really “fair use,” or just a costly shortcut?