
Google has unveiled EmbeddingGemma, a compact open-source embedding model with 308 million parameters (0.3B) that’s designed to run directly on laptops, smartphones, and desktops. At just 200MB of memory, it enables retrieval-augmented generation (RAG), semantic search, and more—even without an internet connection.
Despite its size, EmbeddingGemma delivers embedding quality comparable to models twice as large, like Qwen-Embedding-0.6B, making it a significant step for edge AI and privacy-first computing.
▲ Hugging Face release page
Hugging Face release page:
https://huggingface.co/collections/google/embeddinggemma-68b9ae3a72a82f0562a80dc4
🔥 Why This Matters
Big AI models have dominated headlines, but deploying them on consumer hardware has been a challenge—until now. Google’s EmbeddingGemma is built to bring AI-powered search and reasoning right to your device:
- Tiny footprint: runs under 200MB RAM
- Multilingual: trained across 100+ languages
- Best-in-class under 500M parameters on the MTEB benchmark
- Offline-first: works without internet, ensuring privacy
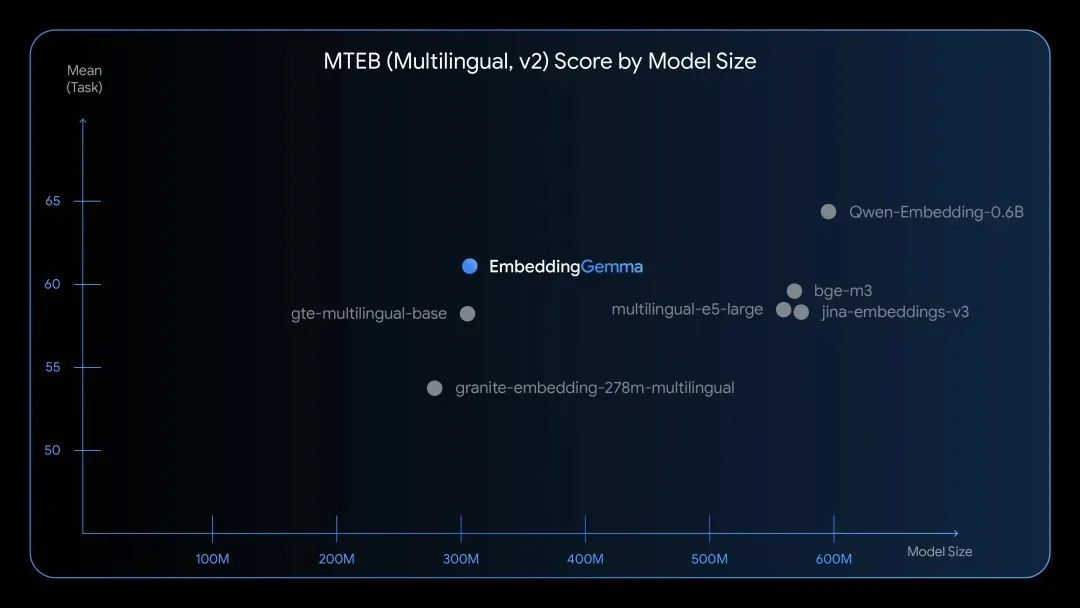
▲ Benchmark: EmbeddingGemma ranks highest among compact multilingual models
⚡ What It Can Do
1. High-quality embeddings for smarter RAG
EmbeddingGemma transforms text into dense vector embeddings, enabling retrieval systems to fetch the most relevant context before a generative model (e.g., Gemma 3) creates an answer.
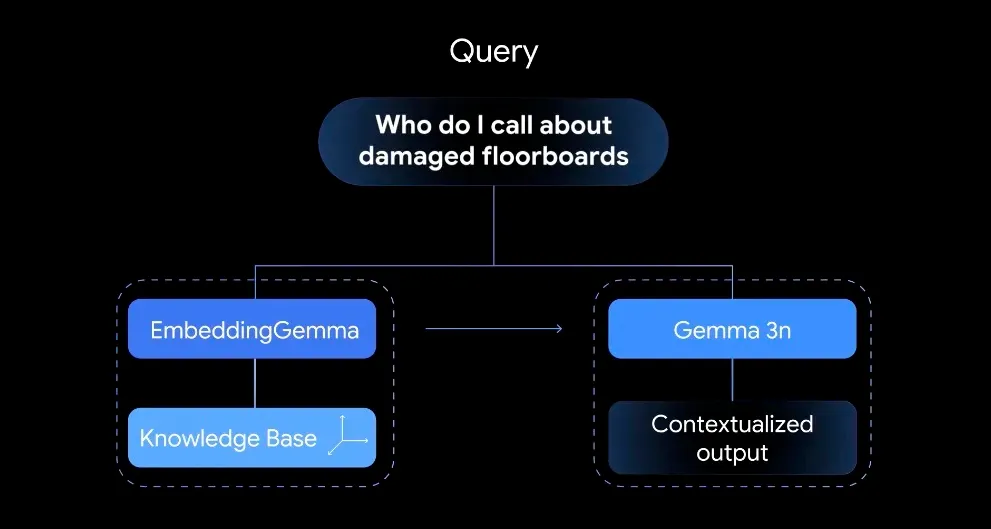
▲ Embedding vectors capture subtle semantic meaning
This means:
- More accurate answers in RAG workflows
- Better semantic search across personal files, emails, and notes
- Reliable performance entirely offline
2. Punches above its weight class
At 308M parameters, EmbeddingGemma outperforms many same-size models and comes close to the much larger Qwen-Embedding-0.6B.
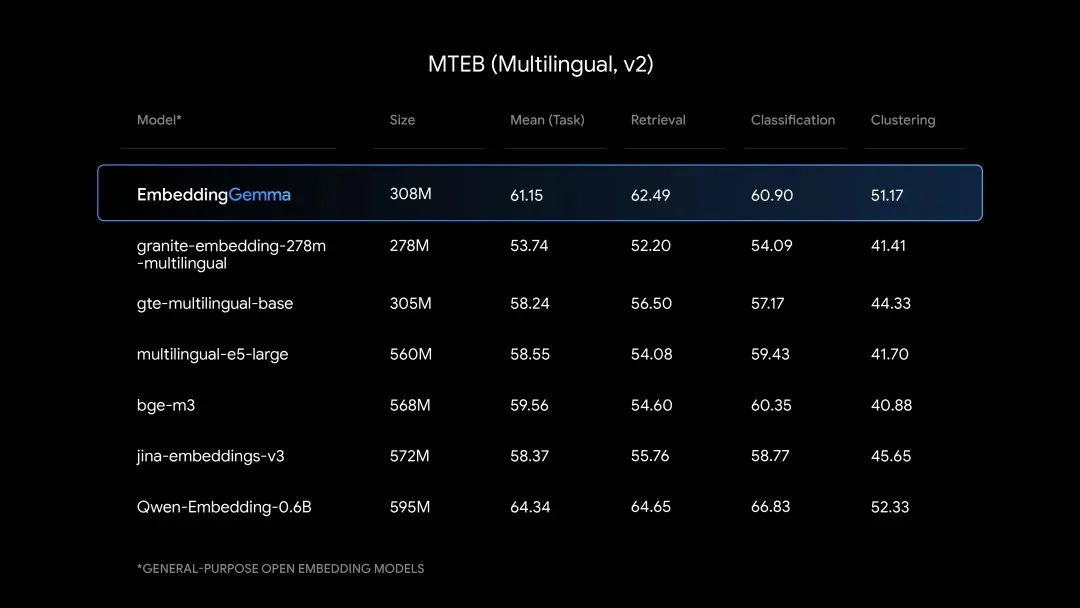
▲ Performance benchmarks: EmbeddingGemma holds its own against larger models
- Matryoshka Representation Learning (MRL) lets developers choose embedding sizes:
- 768D (max quality)
- 128D / 256D / 512D (faster, lighter)
- Inference speed: <15ms per 256 tokens on EdgeTPU
- Optimized via quantization-aware training (QAT) to cut memory below 200MB
3. Private, offline-first AI
EmbeddingGemma prioritizes privacy by running locally on hardware. No cloud dependency means sensitive data stays on your device.
Possible applications include:
- Offline search across files, texts, and notifications
- Personalized RAG chatbots with domain knowledge
- Mobile agents that map queries to function calls in real time

▲ On-device embedding visualization demo (Hugging Face)
Interactive demo:
https://huggingface.co/spaces/webml-community/semantic-galaxy
🏁 The Bigger Picture
EmbeddingGemma reflects Google’s push into lightweight, multilingual, edge AI. By striking a balance between speed, size, and accuracy, it makes powerful AI accessible on everyday devices.
As RAG and semantic search shift from cloud to local environments, models like EmbeddingGemma could be the backbone of next-generation mobile AI experiences—private, fast, and always available.