
Google is back in the search business — but this time, it’s arming AI with something radically different: the ability to truly see and deeply parse web content.
With the rollout of the URL Context feature in the Gemini API (launched May 28 in Google AI Studio), developers can now point Gemini directly at a webpage, PDF, or even an image, and the model will treat that source as the authoritative context for its response.
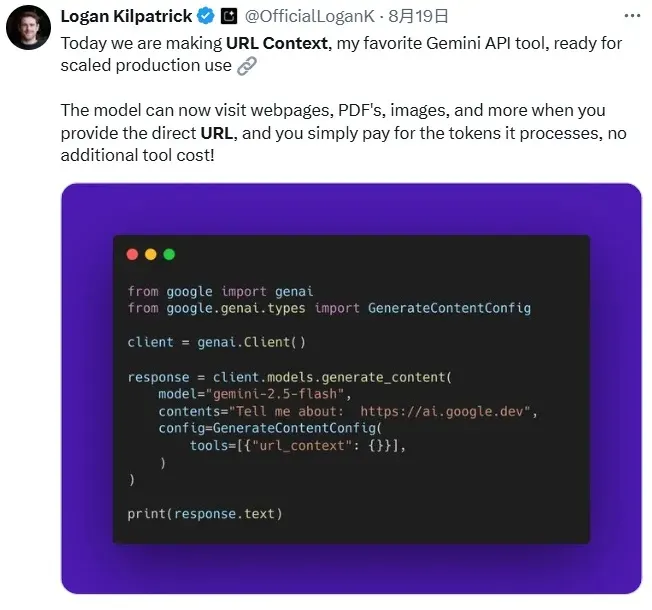
Google product lead Logan Kilpatrick called it his favorite Gemini API feature, even recommending it as a “default-on” tool for developers.

Why This Isn’t Just “Dropping a Link” Into Chat
If you’ve ever pasted a URL into ChatGPT or another AI assistant, you might wonder what’s new here. The difference is depth.
- Traditional chat links rely on generic browser or search plugins, which often only skim snippets or summaries.
- URL Context, by contrast, allows Gemini to ingest all content from a link — up to 34MB per file — and use it as the sole, authoritative reference for generating answers.
That means entire PDFs, footnotes, tables, and even charts are parsed in full fidelity.
What It Can Do
Gemini’s new capability comes with a surprisingly broad skillset:
- Deep PDF analysis: Extracts tables, document structure, even hidden disclaimers in footnotes.
- Multimodal support: Reads and interprets PNGs and JPEGs, including diagrams and charts.
- Flexible file compatibility: Handles HTML, JSON, CSV, and other common formats.
Developers can configure it via API or test it directly in Google AI Studio.
The RAG Debate: Reinventing Context Retrieval
In a widely circulated Towards Data Science piece, Thomas Reid described URL Context as “another nail in RAG’s coffin.”
- Read more: https://towardsdatascience.com/googles-url-context-grounding-another-nail-in-rags-coffin/
For years, RAG (Retrieval-Augmented Generation) has been the industry’s fix for stale or incomplete model knowledge, stitching together pipelines that scrape, chunk, vectorize, and store external data in vector databases.
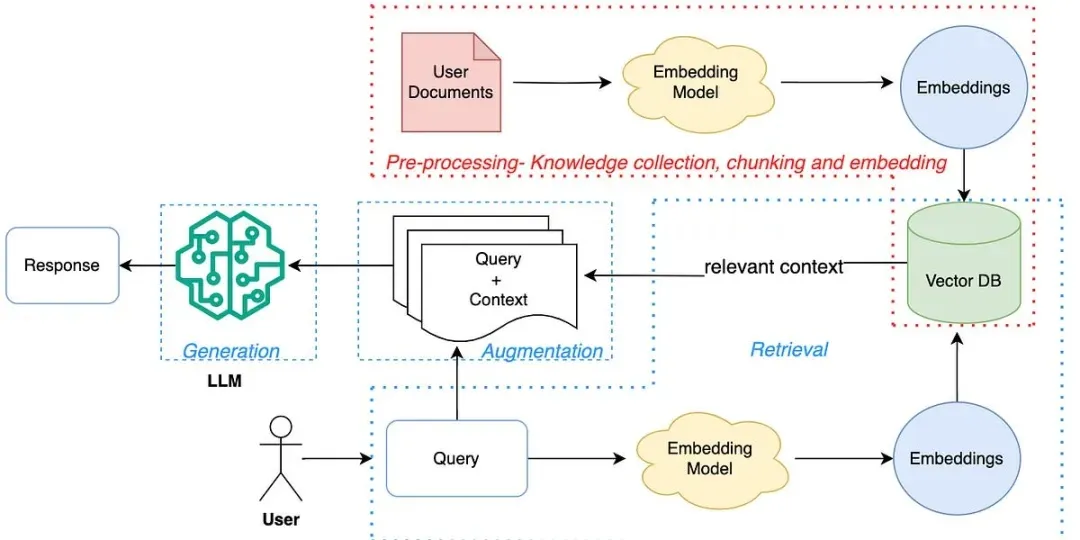
RAG pipeline architecture. Source: Mindful Matrix
URL Context makes that look almost… over-engineered. Instead of building and maintaining complex retrieval infrastructure, developers can just pass Gemini a link — and let the model do the rest.
Tested in the Wild
Reid demonstrated this with a Tesla SEC filing: Gemini extracted total assets and total liabilities directly from a table on page 4 of a 50-page PDF — all from a single URL.
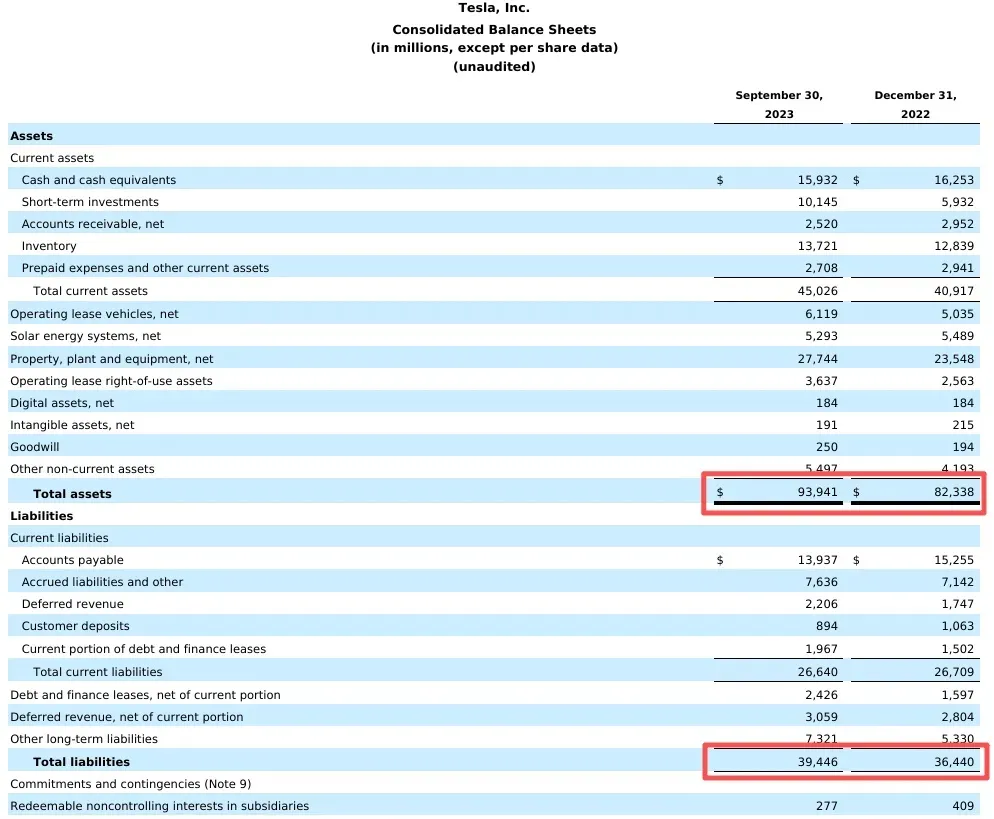
We replicated this in Google AI Studio, and the model nailed it.
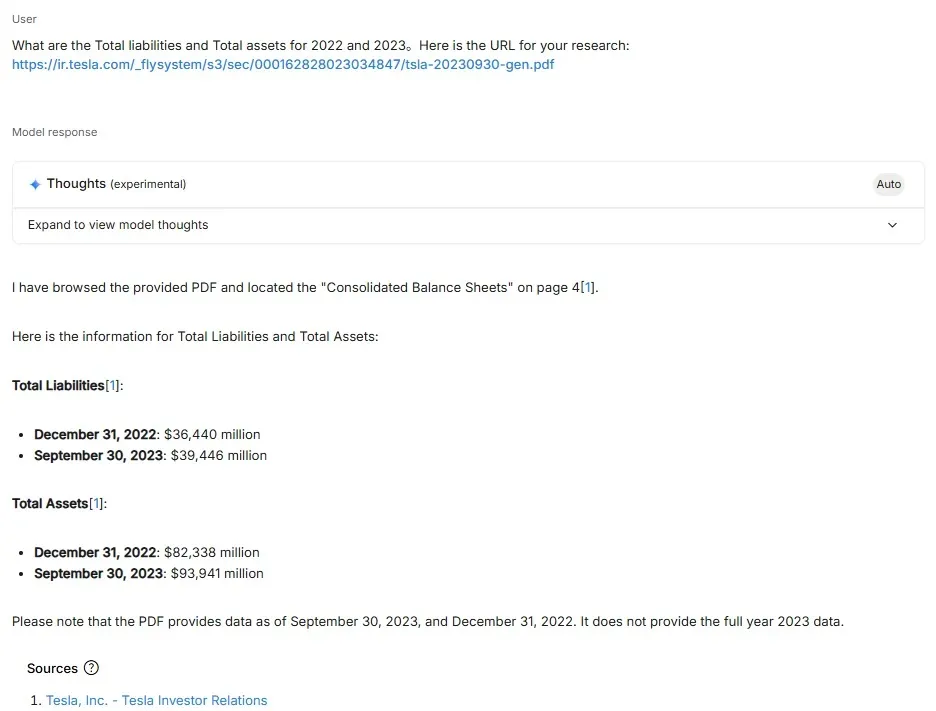
Even more striking: in the same document, an employee exit letter redacted certain dates with *** symbols. The explanation was buried in a footnote. Gemini, via URL Context, picked it up without issue.
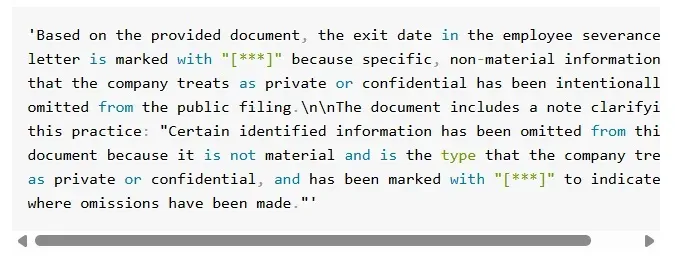
The takeaway? This isn’t just surface reading — it’s legal-document-grade parsing.
How It Works
Behind the scenes, URL Context uses a two-step retrieval system:
- Cache check: Pulls from Google’s internal index for speed and lower cost.
- Live fetch: If uncached (say, a brand-new page), it scrapes in real time.
Limits and caveats include:
- 🚫 No access to paywalled or login-protected content
- 🚫 No overlap with dedicated APIs (e.g. YouTube, Google Docs)
- 📏 20 URLs max per call, 34MB per file
Pricing is simple: you pay per token processed. More content = more tokens = higher bill. This will nudge developers toward precision sourcing instead of shotgun-feeding URLs.
Not the End of RAG, But a Shift in the Landscape
Does this kill RAG? Not quite.
Enterprises still need custom RAG systems for massive private datasets, secure intranets, and fine-tuned retrieval logic. But for public web content, URL Context is a sleek, developer-friendly shortcut.
More importantly, it reflects a bigger industry trend:
Foundational models are internalizing tasks that once required elaborate pipelines.
Scraping, chunking, embedding — work that used to live at the application layer is steadily being absorbed into the model itself.
For developers, that means fewer moving parts, faster prototyping, and more time spent building products — not plumbing.