
Just now, Apple made a major release on Hugging Face:
Instead of a minor update, Apple unveiled two flagship multimodal models — FastVLM and MobileCLIP2.
- FastVLM: Designed for speed, cutting first-token latency to 1/85 of competing models.
- MobileCLIP2: Optimized for efficiency, achieving comparable accuracy to SigLIP while cutting model size in half.
From real-time camera subtitles to offline translation and semantic photo search, these models enable seamless, on-device AI experiences.
And the best part? Both models and demos are already public — ready for research, prototyping, and full production integration.
Real-Time Multimodal AI Without Lag
Why is FastVLM so fast?
The secret lies in Apple’s FastViTHD encoder.
Traditional multimodal models face a trade-off:
- Reduce resolution and lose detail,
- Or keep high resolution but suffer heavy token overhead and latency.
FastViTHD breaks this compromise through dynamic scaling and hybrid design, keeping images sharp while reducing the token load — delivering both clarity and speed.
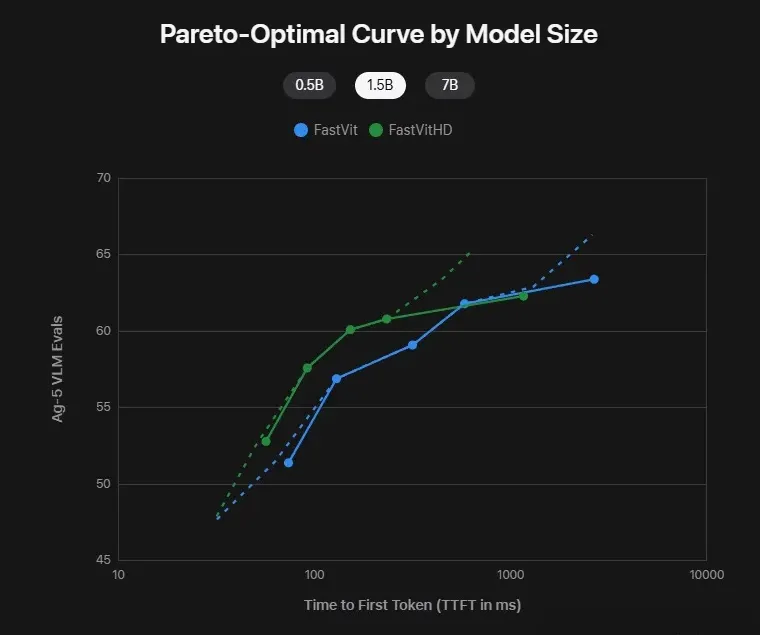
Comparison of FastViT vs FastViTHD: the green curve shifts consistently left and upward, showing faster and more accurate performance.
Performance curves clearly show: whether at 0.5B, 1.5B, or 7B parameters, FastViTHD consistently outperforms its predecessor in both latency and accuracy.
That’s why FastVLM can deliver instant responses without lowering image resolution.
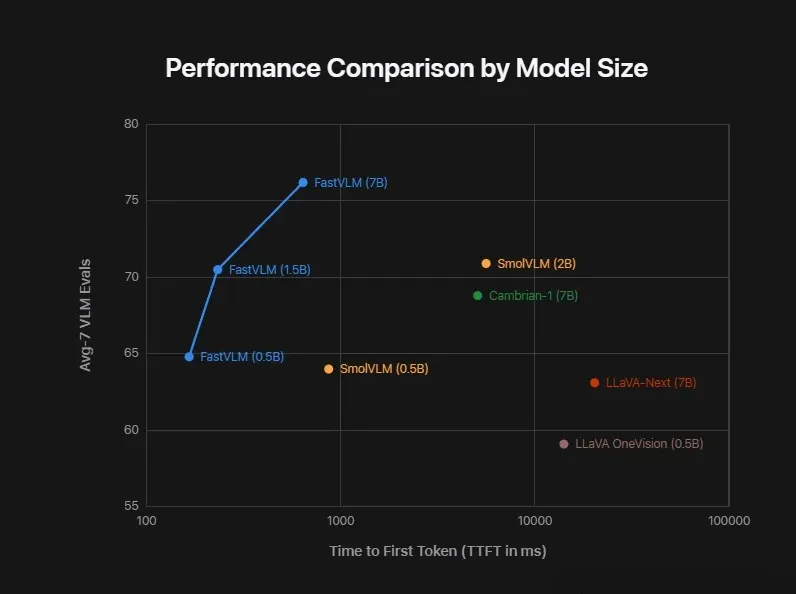
Comparison of average accuracy (y-axis) vs first-token latency TTFT (x-axis) across models.
Apple reports that FastVLM-0.5B reduces TTFT by 85× compared to LLaVA-OneVision-0.5B.
Across benchmarks, FastVLM models (0.5B, 1.5B, 7B) stay in the top-left corner — high accuracy, ultra-low latency.
Unlike conventional solutions, FastVLM doesn’t trade quality for speed — it delivers both.
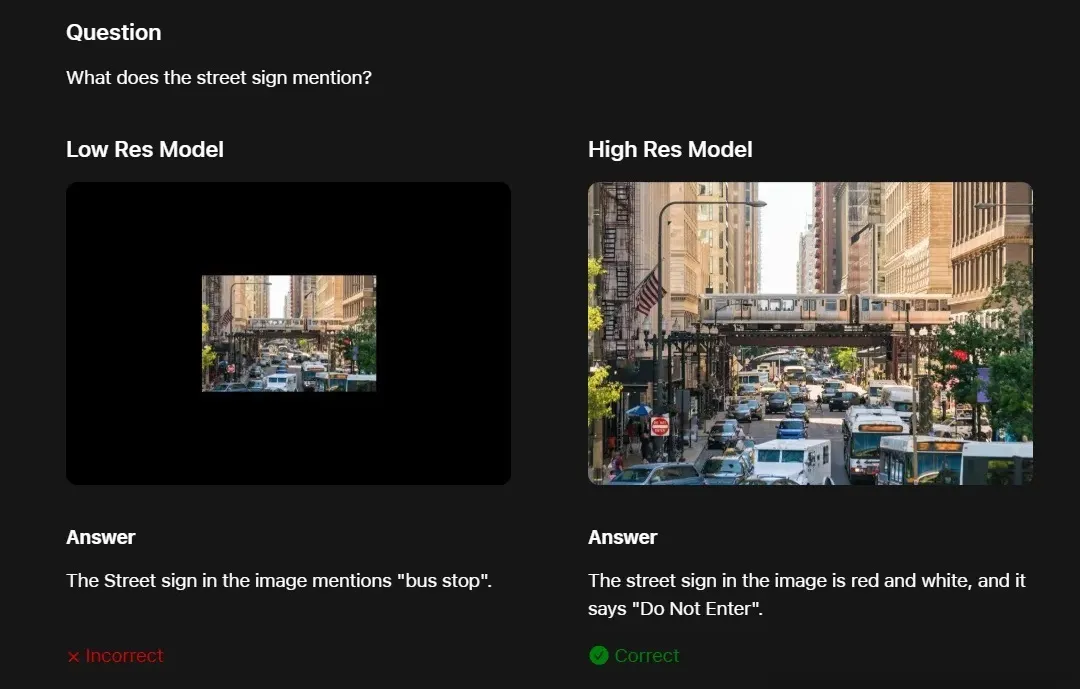
VLM performance with low vs high-resolution inputs. FastVLM maintains accuracy at high resolution with low latency.
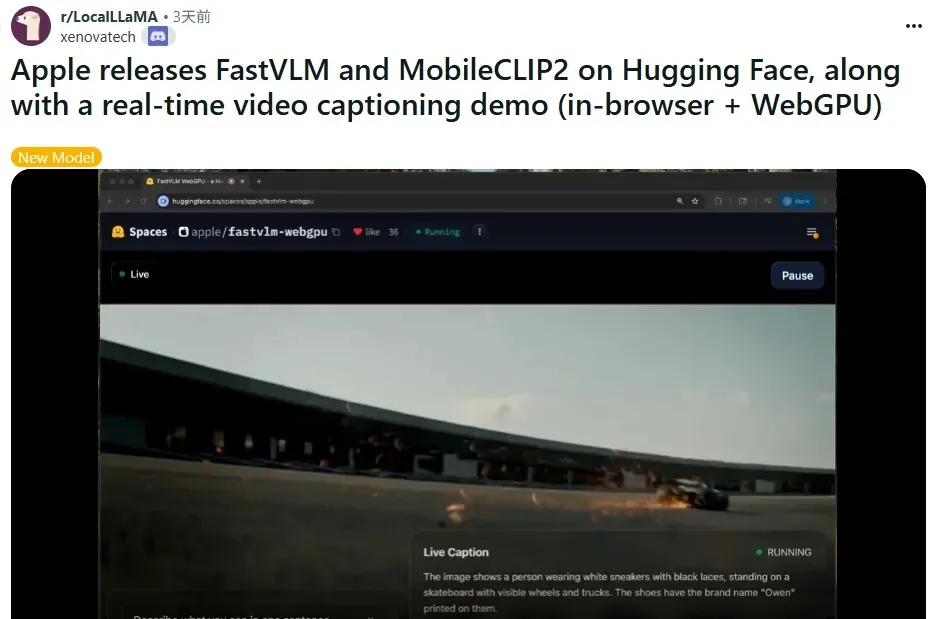
Better still, FastVLM is already on Hugging Face, complete with a WebGPU demo you can try instantly in Safari.
MobileCLIP2: Smaller, Faster, and Just as Smart
If FastVLM is about speed, MobileCLIP2 is about efficiency.
As the 2024 upgrade to MobileCLIP, it leverages multimodal distillation, captioner teachers, and data augmentation to compress intelligence into a lighter package — reducing size without sacrificing understanding.

This shift means tasks like image retrieval and captioning can now run directly on iPhones, without cloud processing.
- No uploads required,
- Instant results,
- More private and secure.
MobileCLIP2’s performance curve sits at the top-left of the accuracy-latency plot, showing a strong balance of high precision with lower latency.
Highlights:
- S4 model: Matches SigLIP-SO400M/14 accuracy on ImageNet-1k, with only half the parameters.
- On iPhone 12 Pro Max, latency is 2.5× lower than DFN ViT-L/14.
- B model: +2.2% accuracy improvement over MobileCLIP-B.
- S0/S2 models: Deliver near ViT-B/16 precision, but with significantly smaller size and faster speed.
From Demo to Integration: Two Steps to Production
Apple didn’t just drop the models — it paved the entire pipeline.
-
Try the demos:
- FastVLM WebGPU Demo on Hugging Face → real-time camera subtitles in Safari.
- MobileCLIP2 inference cards → upload an image or text prompt for instant results.
-
Integrate with Core ML:
Developers can use Core ML + Swift Transformers to bring these models into iOS or macOS apps directly.- Works with both GPU and Neural Engine,
- Optimized for performance and energy efficiency.

This means “running large models on iPhone” is no longer just a demo — it’s now practical for features like album search, live translation, and subtitle generation.
Real-World Reactions: “Unbelievably Fast”
It’s hard to appreciate from specs alone — the magic is in real-world use.
In the FastVLM WebGPU demo, simply point your iPhone camera at printed text, and recognition feels instant.
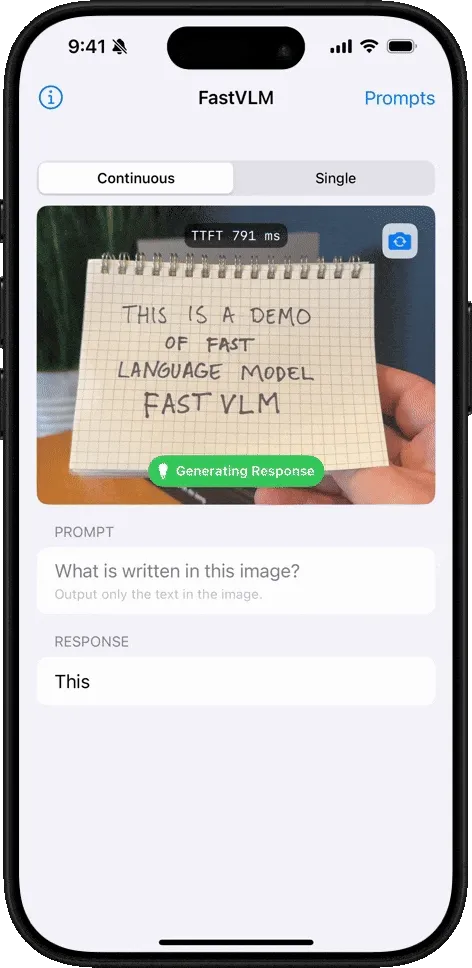
On Reddit, early testers rave:
“It’s unbelievably fast. Even blind users with screen readers can follow along in real time. Holding the phone sideways while walking and typing Braille — still no lag.” — r/LocalLLaMA
Another added:
“FastVLM delivers efficient and accurate image-text processing. It’s faster and sharper than comparable models.” — r/apple
From accessibility breakthroughs to technical validation, the consensus is clear: FastVLM isn’t just fast — it’s reliably fast.
FastVLM vs MobileCLIP2: Which Should You Use?
It depends on your needs:
- FastVLM → For creators who want instant subtitles and live multimodal interaction.
- MobileCLIP2 → For tasks like offline translation, photo search, and private inference.
- Or combine both: subtitles + retrieval in one workflow.
⚠️ A note of caution: WebGPU compatibility varies across browsers and devices, and on-device AI still involves trade-offs between compute and battery life.
Even so, Apple’s Hugging Face release marks a turning point: not just models, but demos, toolchains, and docs all delivered to the community.
From speed to efficiency, from demo to integration, FastVLM and MobileCLIP2 send a clear signal:
Running large-scale AI directly on iPhone is no longer futuristic — it’s happening now.